생성형 AI 환각 줄이는 기업용 RAG, 표+이미지까지 찾아야 게임체인저 (2)
생성형 AI의 환각을 줄이는 대안으로 RAG(검색증강생성) 기술이 부각되고 있지만, 복잡한 표와 차트, 이미지까지 해석해내는 RAG는 많지 않습니다. 기업용 RAG의 필요성과 올거나이즈의 기업용 RAG 방법론, 성능 향상을 위한 전략을 공유합니다.

기업용 RAG 1편에서는 RAG의 개념과 작동 원리, 고성능 리트리버의 중요성과 RAG 성능을 높이기 위한 기술적 문제들에 대해 설명 드렸습니다.
 Allganize Korea
Allganize Korea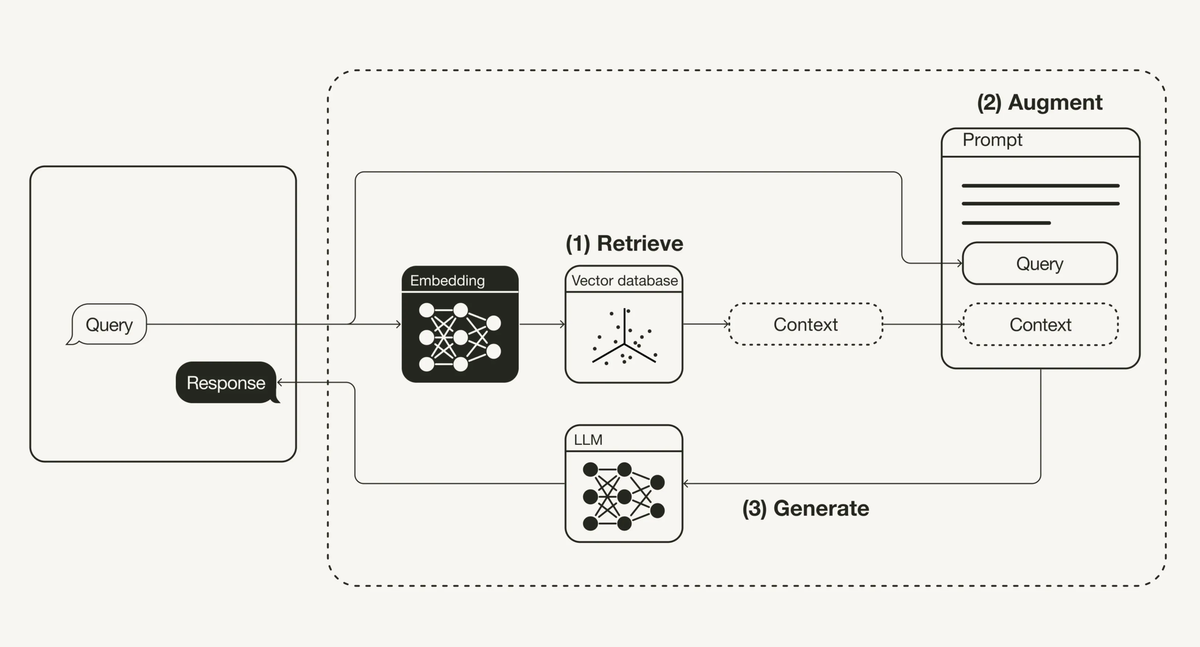
2편에서는 본격적으로 기업의 복잡한 문서에 포함된 차트와 이미지를 해석하고 답을 잘 찾아서 RAG의 성능을 높이는 구체적인 사례를 보여드리고자 합니다.
올거나이즈 RAG 팀 이정훈 팀장이 차트와 이미지가 포함된 문서의 RAG 전략에 대한 글을 작성했습니다.
기업용 RAG의 필요성
최근 많은 AI 기업이 RAG 방식으로 질문에 대한 답변을 제공하고 있습니다. 대부분의 RAG 제품이 단순한 형태의 문서 혹은 간단한 질문에 대해서는 정답을 생성합니다.
하지만 문서에 포함된 차트 혹은 이미지에 대한 질문을 하면 오답을 생성하거나 답변 할 수 없다고 생성하는 경우가 많습니다.
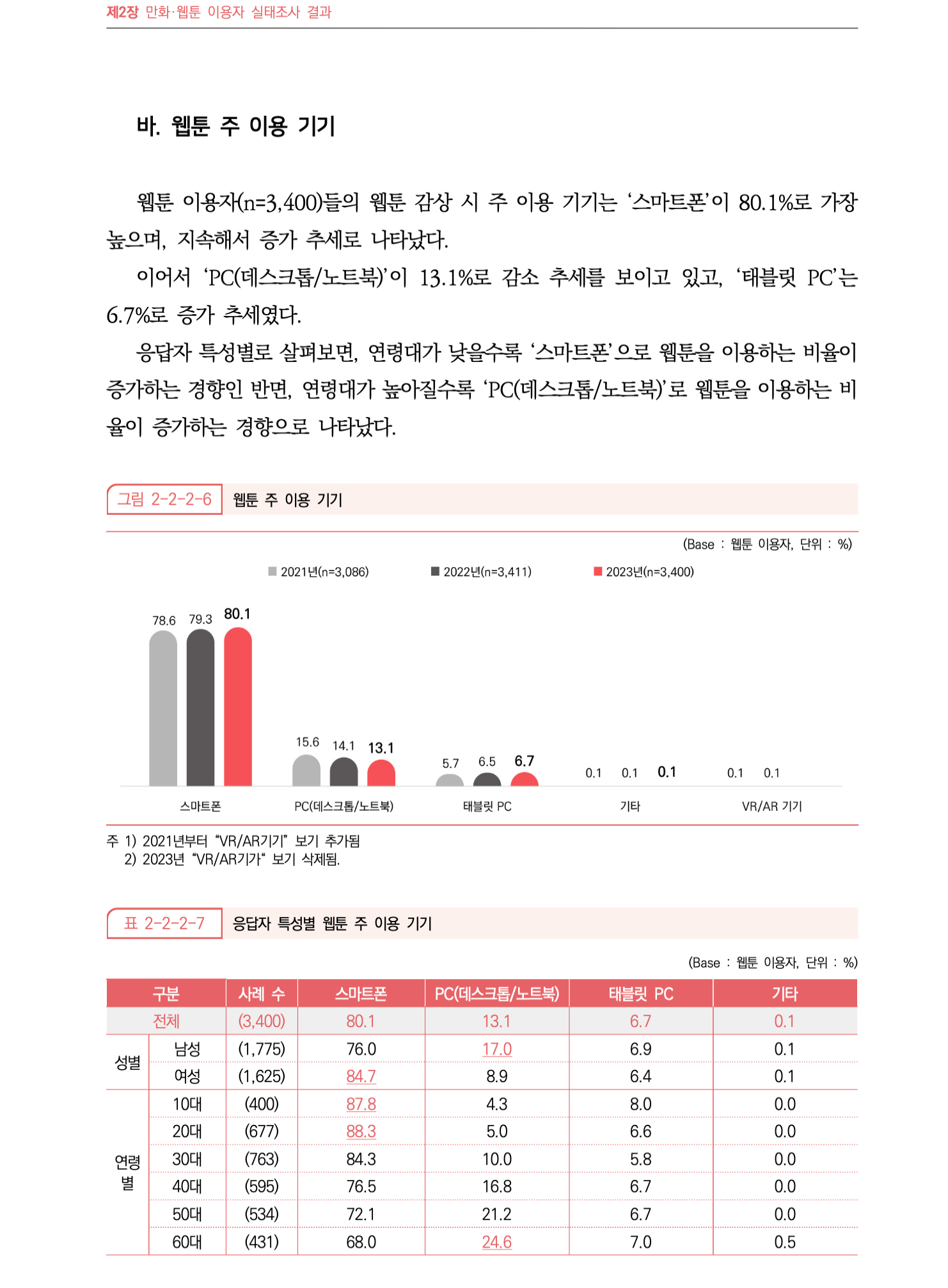
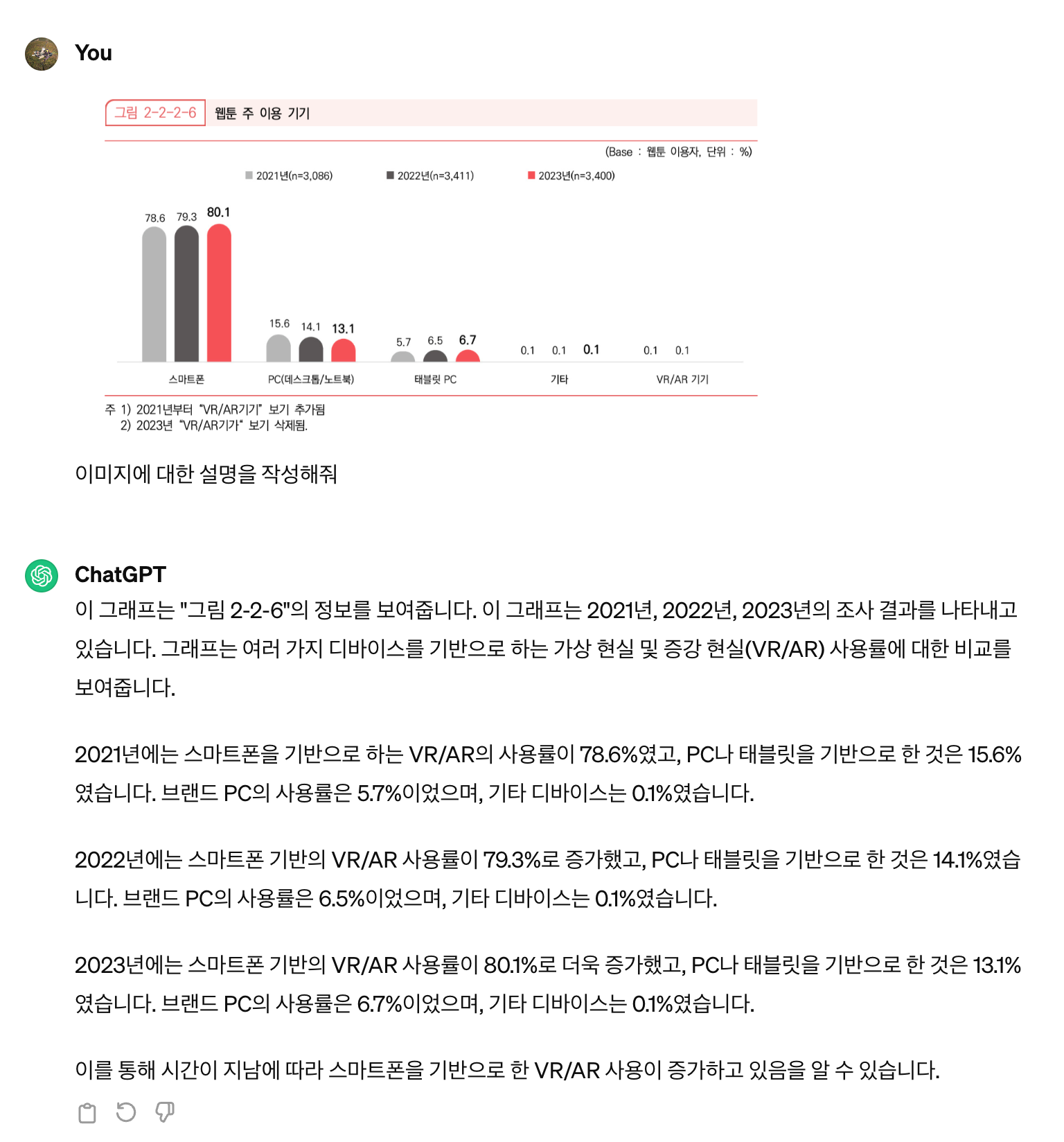
아래의 페이지를 기반으로 “웹툰을 볼 때 스마트폰으로 본 비율은 2023년 기준 2021년 대비 몇 퍼센트 증가했어?” 질문에 대해 답변이 나오는지 확인해 보겠습니다.
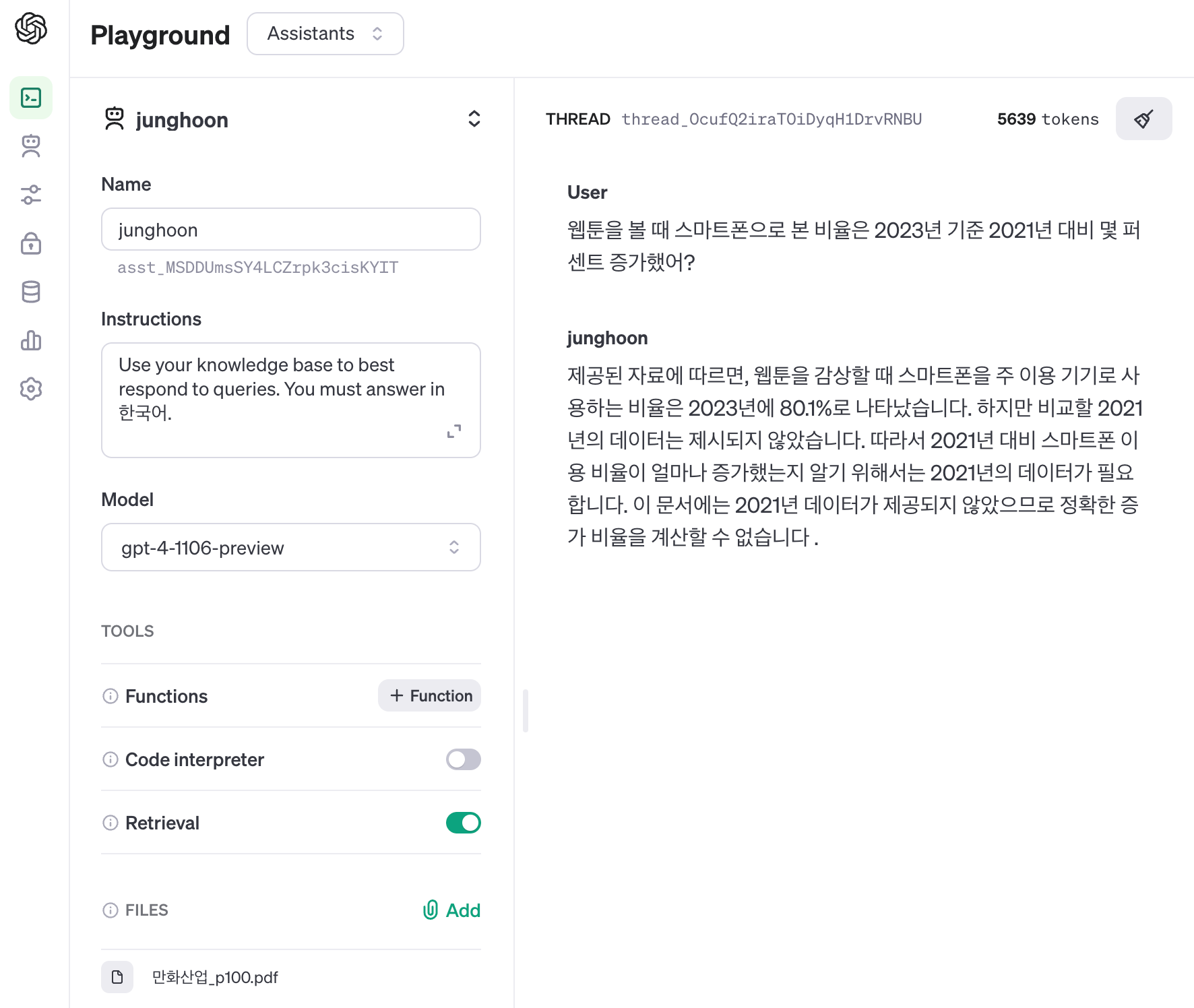
OpenAI의 Assistants로 Files에 위의 페이지를 업로드 후, 질문을 했습니다.
Assistants는 다음과 같이 답변했습니다.
“제공된 자료에 따르면, 웹툰을 감상할 때 스마트폰을 주 이용 기기로 사용하는 비율은 2023년에 80.1%로 나타났습니다. 하지만 비교할 2021년의 데이터는 제시되지 않았습니다. 따라서 2021년 대비 스마트폰 이용 비율이 얼마나 증가했는지 알기 위해서는 2021년의 데이터가 필요합니다. 이 문서에는 2021년 데이터가 제공되지 않았으므로 정확한 증가 비율을 계산할 수 없습니다 .”
2021년 스마트폰 비율을 알 수 없기 때문에 비율을 계산할 수 없다고, 답변을 생성했습니다.
올거나이즈의 Alli는 아래와 같이 답변을 생성했습니다.
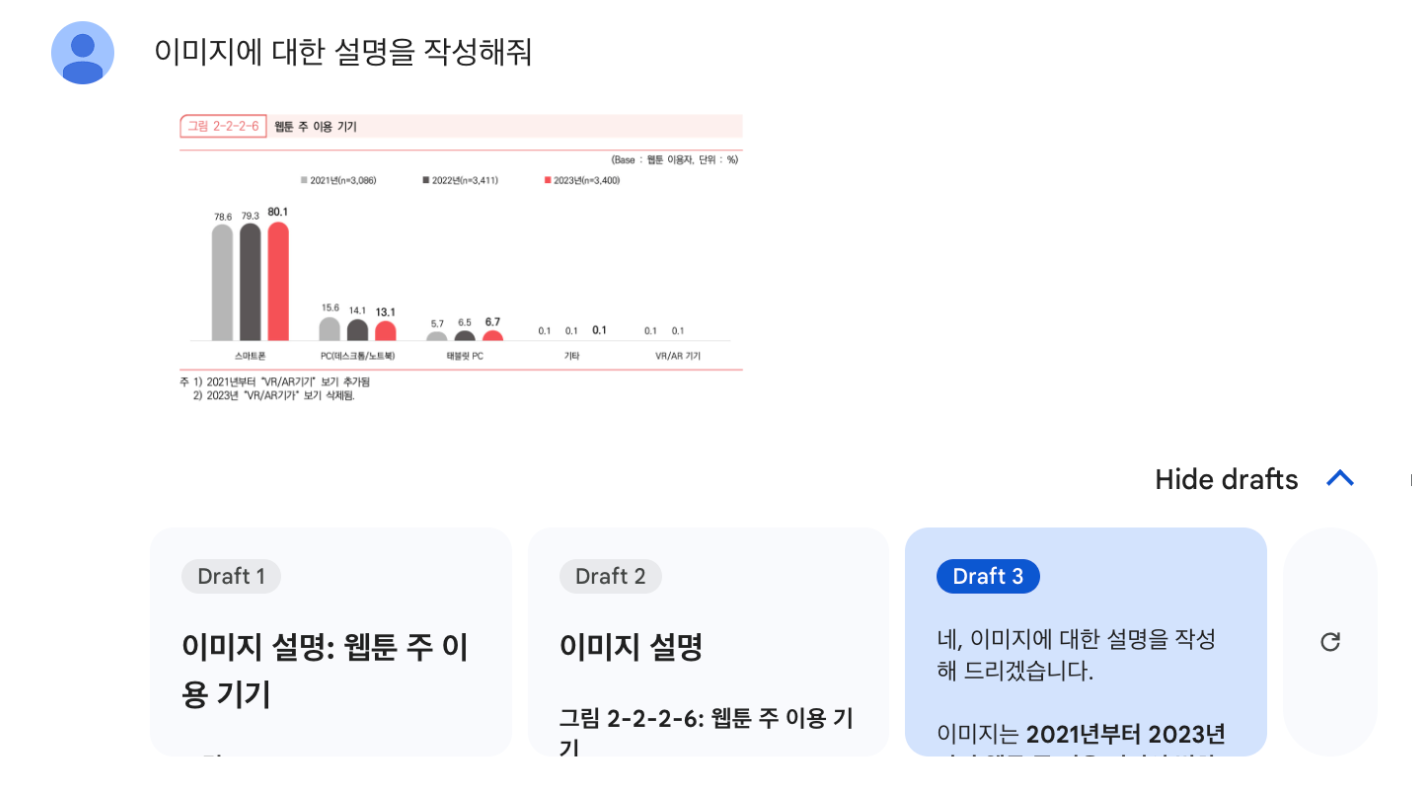
“2021년에 웹툰을 스마트폰으로 본 비율은 78.6%였고, 2023년에는 80.1%로 예상됩니다. 따라서 2023년 기준으로 2021년 대비 약 1.5퍼센트 증가할 것으로 예상됩니다”
그림 2-2-2-6의 차트의 가장 좌측 스마트폰 그래프를 보면 2021년 스마트폰 이용자 비율은 78.6%이고 2023년의 비율은 80.1%입니다. 즉, 1.5% 차이가 증가했으므로 Alli의 답변은 정답입니다.
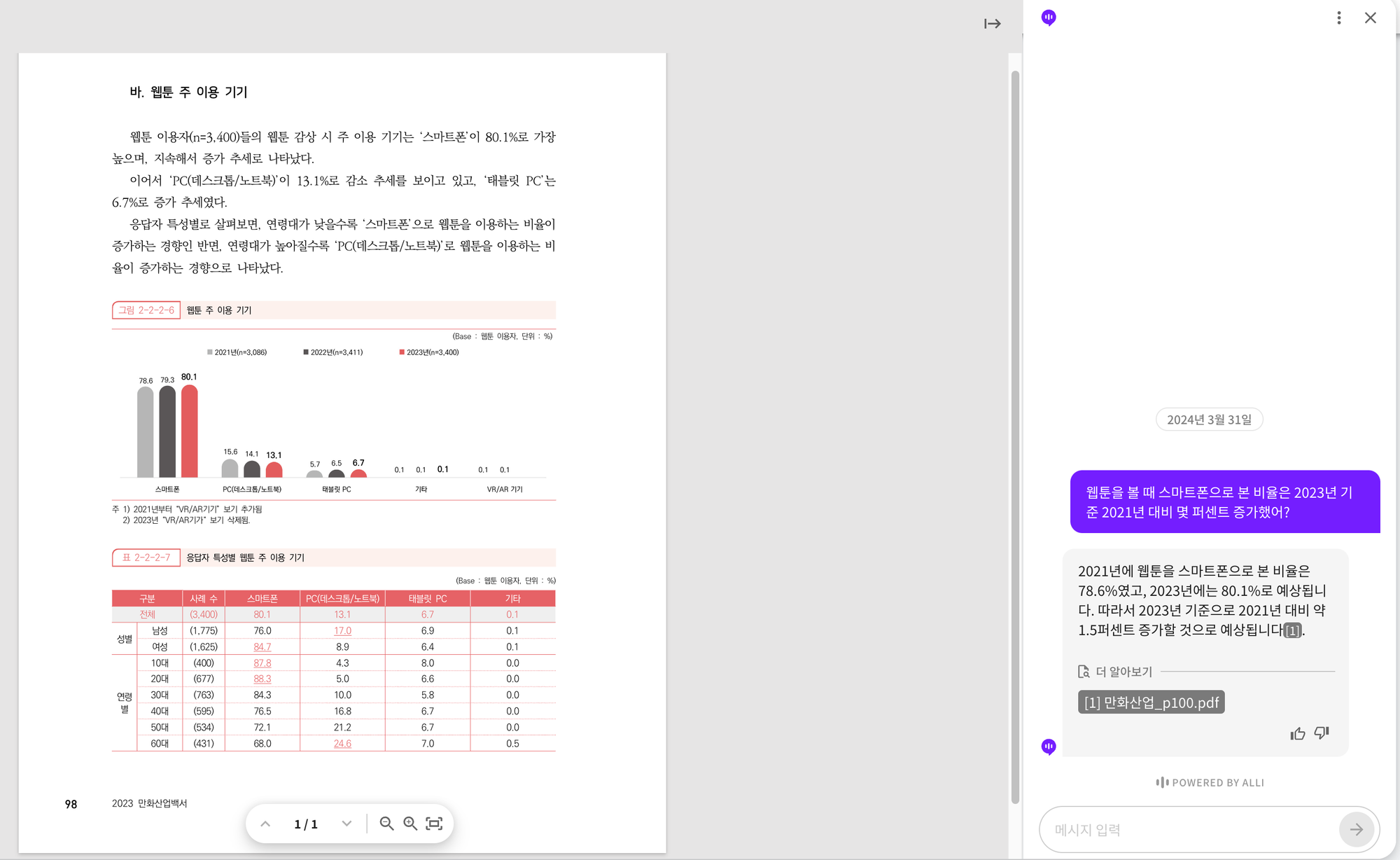
2023년의 비율은 하단의 표에서 얻을 수 있었다고 쳐도, 2021년의 비율은 이미지에 있는 차트를 통해서만 알 수 있습니다.
올거나이즈의 Alli는 어떻게 문서의 이미지로 있는 2021년 스마트폰 이용자 비율을 알 수 있었을까요?
올거나이즈의 기업용 RAG 방법론
문서에 포함된 차트를 해석하는 방법은 다양합니다. 하지만 문서에서 이미지를 찾는 방법이 제일 선행되어야 합니다.
Object Detection
Yolo 같은 Object Detection 방법을 사용해도 되지만, 문서에 특화되어 있지는 않습니다.
올거나이즈에서는 ESNet을 백본 네트워크로 사용한 PP-PicoDet을 사용해, 문서의 figure를 찾았습니다.
보통 Object Detection에서 주로 사용하는 CoCo 데이터 셋은 이미지에 존재하는 물체를 타겟으로 합니다.
문서는 일반 이미지와 형태가 다르기 때문에, Publaynet이라는 문서 정보가 annotation이 되어 있는 데이터를 주로 사용합니다.
다양한 문서 형태에 figure, table, caption, text 정보가 수십만 장의 문서 이미지가 태깅되어 있고 PP-PicoDet 모델 또한 해당 데이터를 사용했습니다.

{kind=link}
문서에 Object Detection을 적용하면 아래와 같이 figure와 관련된 부분을 찾을 수 있습니다.
문서의 figure를 찾은 후, 그 부분을 crop 하여 descripion을 생성하는 데 사용합니다.

만약 문서에서 이미지를 찾지 못한다면 이후에 description을 생성하는 과정을 아예 시작할 수 없습니다.
그래서 image detection의 성능은 매우 중요합니다.
OCR
문서의 이미지를 해석하는 방법은 다양합니다.
가장 쉬운 방법은 OCR을 적용해 문서에 포함된 텍스트를 모두 가져오는 방법입니다.
최근의 LLM 성능이 계속 좋아졌기 때문에, 텍스트만 추출해서 프롬프트에 입력되어도 어느 정도 유사하게 답변할 가능성이 커집니다.
아래는 Google OCR 결과입니다. 78.6, 79.3의 텍스트를 추출했습니다.
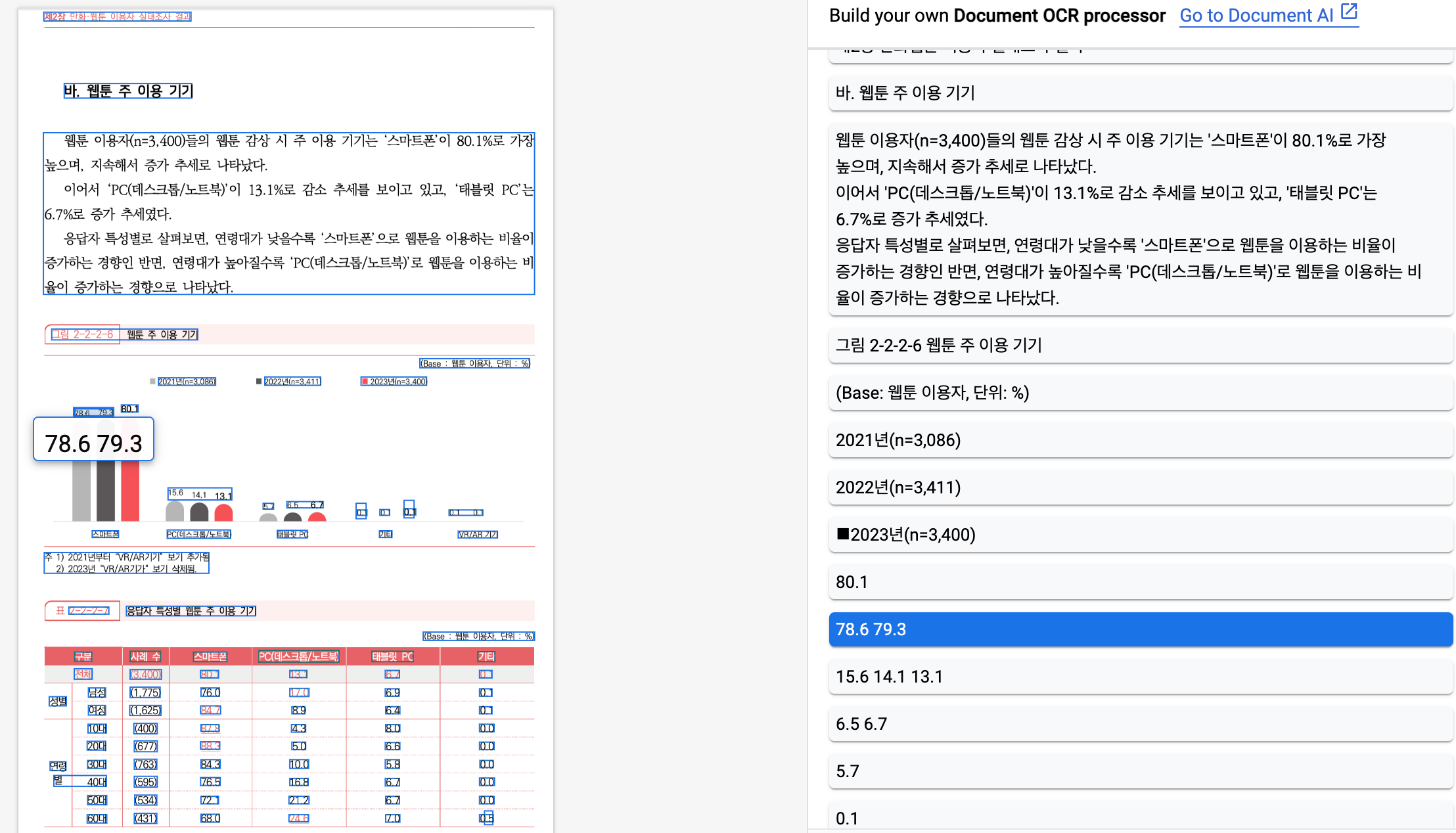
하지만, 해당 방법의 문제점은 OCR로 추출된 텍스트들이 어떤 것과 연관이 있는지 명확히 알 수 없다는 것입니다.
또한, 아래와 같이 차트에 텍스트가 거의 없는 경우라면 더욱더 해석하기 어렵습니다.

Image Captioning
하지만, OCR로 단순히 텍스트만 뽑아내는 것이 아닌, 모델을 이용해 이미지의 description을 생성한 후, 프롬프트에 입력하면 더 좋은 답변이 생성될 것입니다.
LMM(Large Multimodal Models)이 주목받기 전에도 Image to Text 모델은 사용되고 있었습니다.
올거나이즈에서도 과거에 Image Caption 모델을 사용했을 때는, 생성되는 텍스트가 짧아 고객이 체감할 만한 성능 향상은 없었습니다.
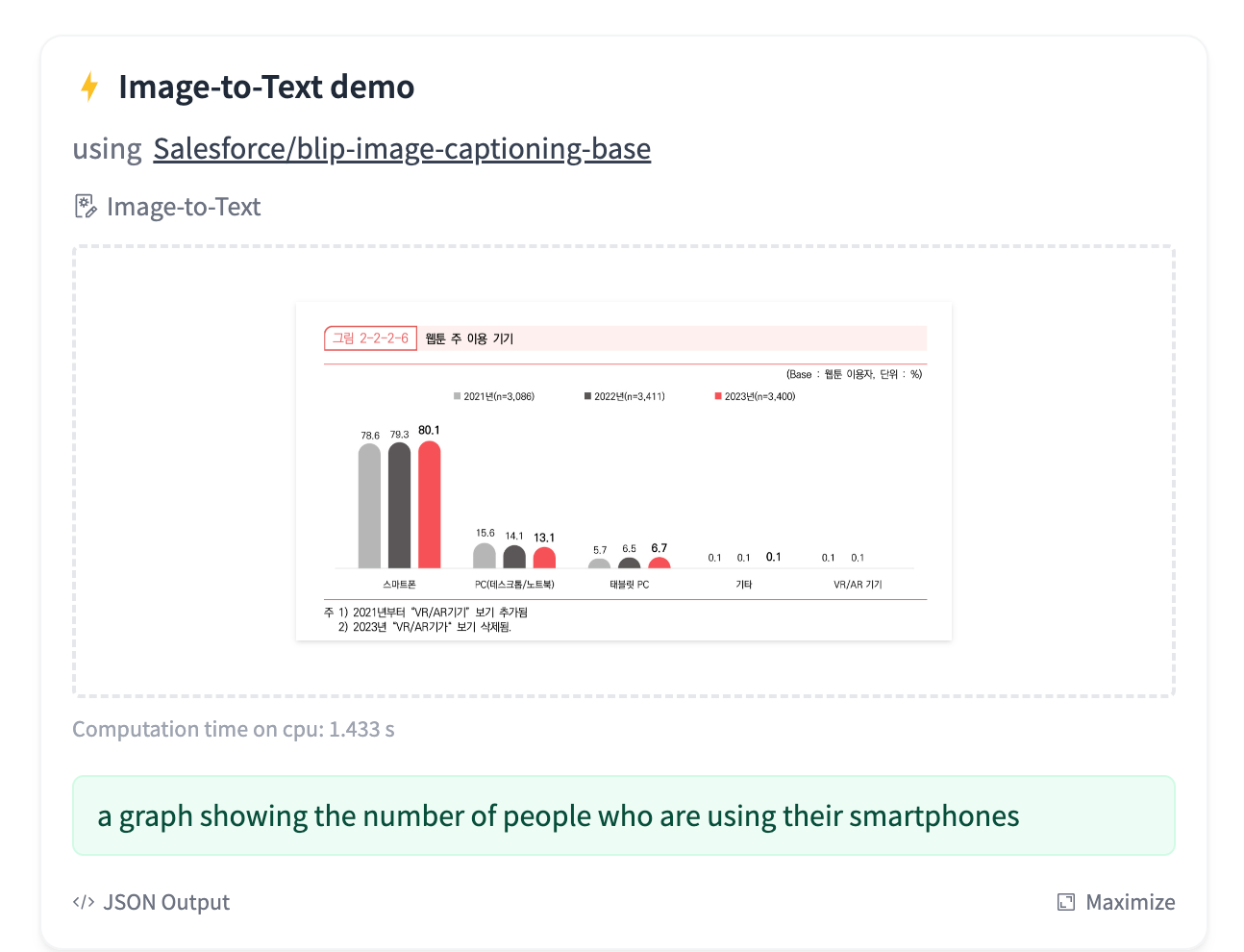
위에서 사용했던 차트를 사용해 Image Caption을 생성하면, 아래와 같이 “스마트폰을 사용하는 사람들의 수”가 생성됩니다.
이런 텍스트는 사용자들이 하는 질문과 관련 없는 정보이며 답변 생성에 크게 도움 되지 않습니다.
LMM (Large Multimodal Models, 거대멀티모달모델)
현재는 다양한 LMM 모델이 나와 있고, 놀라운 description 성능을 보여주고 있습니다.
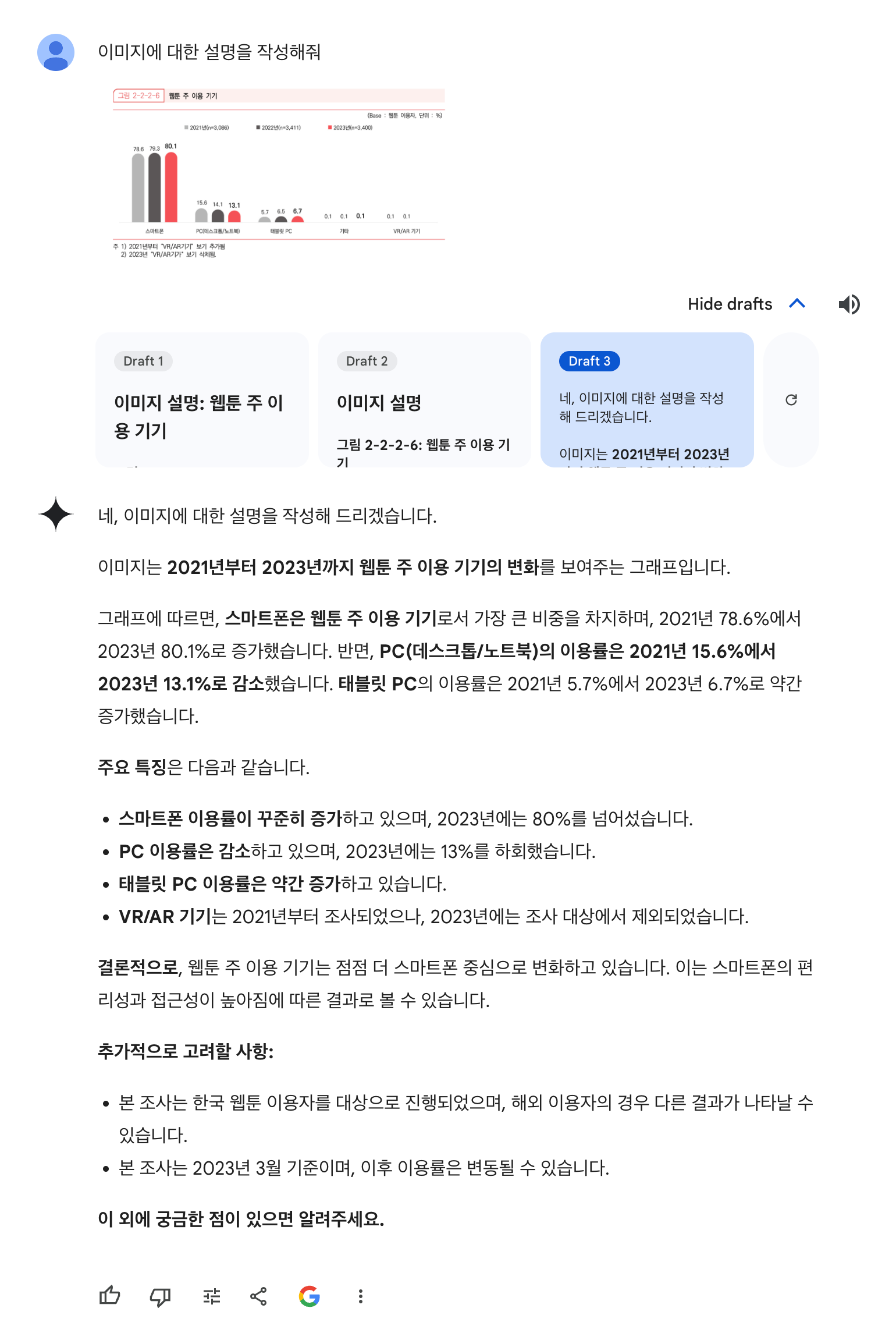
아래는 ChatGPT를 사용한 이미지에 대한 description 결과입니다.
결과를 보면 차트에서 뽑아낼 수 있는 모든 정보를 뽑아냈습니다.
아래는 Google의 Gemini를 사용한 설명입니다.
마찬가지로 차트에서 뽑을 수 있는 이미지를 잘 설명하고 있습니다.
해당 description을 프롬프트에 context로 사용자의 질문과 함께 넣어준다면 답변을 얻을 수 있습니다.
더 나은 기업용 RAG를 위한 전략
그렇다면 문서에서 차트를 찾고, LMM을 이용해 이미지에서 description을 생성하면 모든 게 해결될까요?
LMM이 위에 예시같이 좋은 description을 생성한다면 행복하겠지만, 잘못된 description을 생성하는 경우도 많습니다.
예를 들어, 아래는 OpenAI GPT4_TURBO_VISION 모델에 API로 Call을 보내 얻은 결과입니다.
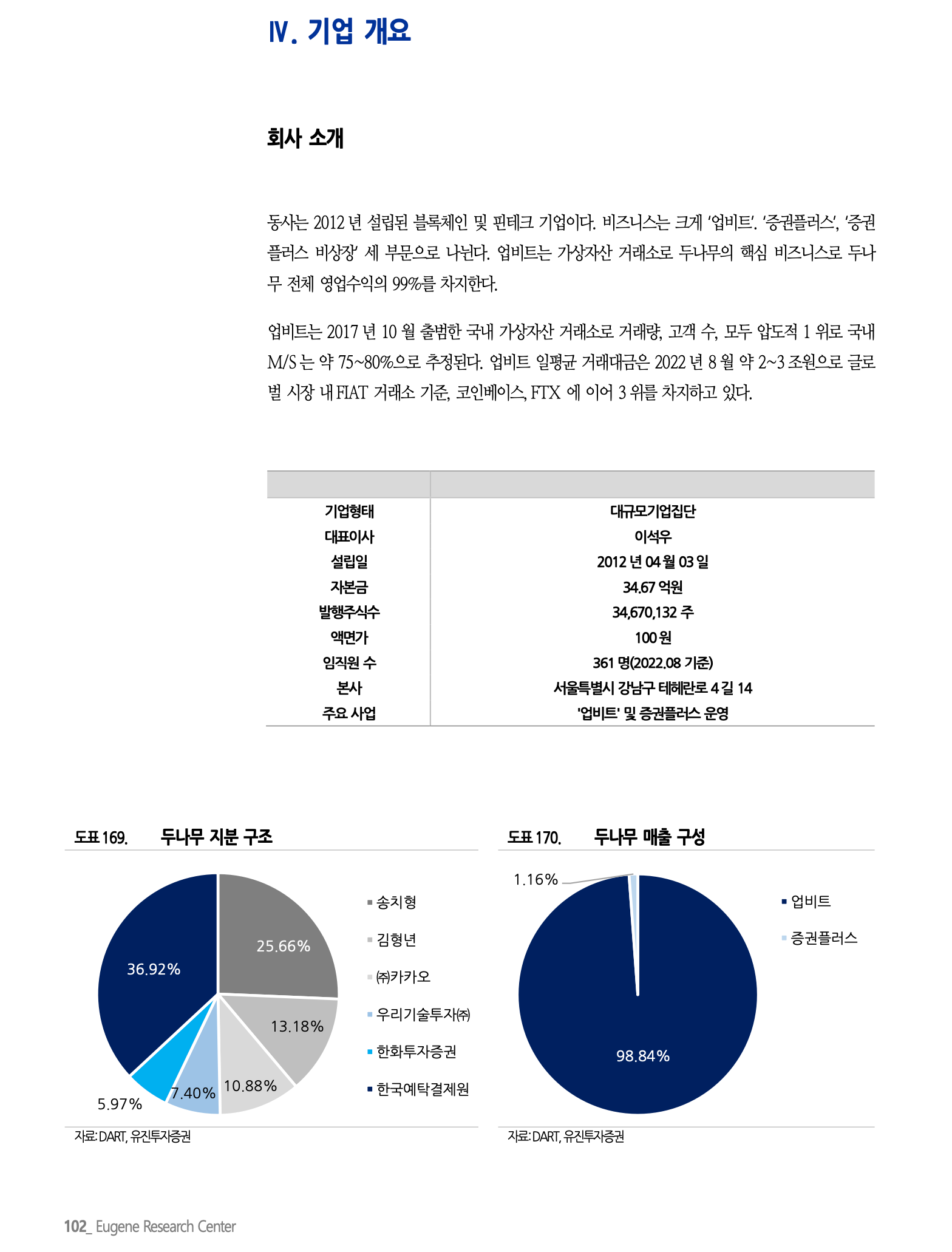
이 이미지에는 두 개의 원형 차트가 나타나 있습니다. 왼쪽 차트는 '도표 169. 단말기 제조 국적'이라는 제목이 있고, 오른쪽 차트는 '도표 170. 단말기 매출 구성'이라는 제목이 있습니다.
왼쪽 차트는 여러 색상으로 구분된 여섯 개의 부문으로 나뉘어져 있으며, 각 부문은 단말기 제조 국적의 비율을 나타냅니다.
가장 큰 부문은 '중국'으로 36.92%를 차지하고 있고, 그 다음으로 '미국'이 25.66%를 차지합니다. '한국'은 13.18%, '유럽기타'는 10.88%, '일본'은 7.40%, '대만'은 5.97%의 비율을 보여줍니다.
오른쪽 차트는 거의 전체가 '알파벳'으로 표시된 단일 색상으로 되어 있으며, 이는 98.84%를 차지합니다. 나머지 작은 부분은 '콜럼블루스'로 1.16%를 차지합니다. 두 차트 모두 하단에 '자료:DART, 파트너스'라고 출처가 표시되어 있습니다. 이 차트들은 아마도 어떤 시장이나 산업에 대한 단말기 제조 국적과 매출 구성을 분석한 자료로 보입니다.
좌측 차트와 우측 차트의 퍼센트는 잘 맞췄지만, 속성 이름은 틀린 것을 확인할 수 있습니다.
이러한 케이스에는 단순히 이미지만 넣고 description을 생성하는 것이 아닌, description을 생성할 때 위아래 텍스트를 배경 지식으로 함께 넣어준다면 환각(hallucination)을 줄일 수 있습니다.
이러한 케이스 이외에도 다양한 문제 상황들이 있습니다.
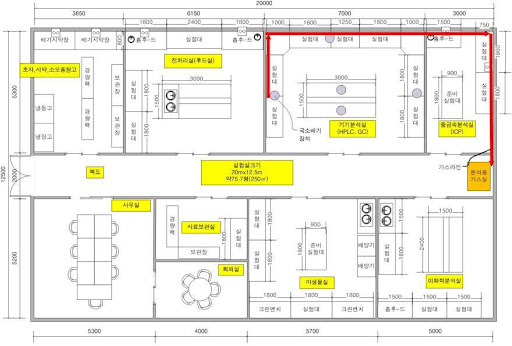
예를 들어, 복잡한 이미지는 토큰 수의 제한으로 인해 질문과 관련된 description이 생성되지 않는 경우가 많습니다.
아래와 같은 도면의 description을 생성하는 것은 쉽지 않습니다.
올거나이즈에서는 이렇게 다양한 상황과 고객의 질문을 처리하기 위한 기술을 발전시키고 있습니다.
제대로 된 기업용 RAG를 고민하신다면, 올거나이즈에 문의주세요.
