[금융 LLM 시리즈 5] 금융 AI 모델 학습 파이프라인 및 Llama3 이후 전략
금융 LLM 시리즈 5편, 금융 모델 제작 후, 새로운 오픈소스 모델이 나오더라도 학습과 평가에 엔지니어의 시간이 많이 들어가지 않도록 학습 파이프라인을 자동화해야 합니다. 메타의 Llama 3 공개 이후 모델 기대체와 평가 데이터도 바뀌어야 하는 상황이 왔습니다. 올거나이즈 AI팀의 고민과 진행과정을 공유합니다.

![[금융 LLM 시리즈 5] 금융 AI 모델 학습 파이프라인 및 Llama3 이후 전략](https://storage.ghost.io/c/e6/c4/e6c4e989-7bf7-45ef-8e98-79671db8ba4c/content/images/size/w2000/2024/05/-----------2024-05-20-------11.04.01-1.png)
금융 LLM 시리즈는 오픈소스 모델을 기반으로 성능 좋은 금융 AI 모델을 만들기 위한 올거나이즈 AI 팀의 고민과 진행 과정을 공유하고 있습니다.
이제 마지막 편, 금융 AI 모델의 학습 파이프라인 및 자동화에 대한 내용을 올거나이즈 신기빈 CAIO가 전하면서 마무리하겠습니다.
지금까지 금융 LLM을 만들기 위해 계획하고 실행하는 방법에 대해서 올거나이즈 AI 엔지니어들의 생생한 경험담을 들어보았습니다.
하지만 그것이 끝이 될 수 없습니다. 올거나이즈의 금융 특화 LLM인 Alpha-F(EEVE)를 배포하고 다음 모델을 계획하는 와중에도 WizardLM2, Llama3, Qwen1.5등 새로운 baseline모델이 속속 공개되었습니다.
학습 방법은 어떤가요? 이제 거의 상식이 된 DPO를 넘어서 mergekit을 이용한 모델 합성이 주요한 방법론으로 자리잡아가고 있습니다. 이렇게 정신없이 발전하는 환경에서 회사가, 엔지니어가 갖추어야하는 경쟁력은 무엇일까요?
올거나이즈는 좋은 금융 모델을 만들기를 원했고, 좋은 금융모델의 특징을 정의했고, 그 특징들을 정량화할 수 있는 데이터셋을 만들었습니다. 이제는 공개된, 학습한 모델이 어느 정도 점수를 얻는지 평가할 수 있어야합니다. 그리고 그 평가는 공정하고 믿을 수 있어야합니다. 무엇보다도 평가에는 비용, 특히 엔지니어의 시간이 적게 들어가야만 합니다.
올거나이즈 AI 팀은 Alpha-F(EEVE) 배포 이후 어떤 새로운 baseline 모델이 나오더라도 학습/평가에 엔지니어의 시간이 많이 들어가지 않도록 pipeline을 정리하고 자동화 시키는데 많은 시간을 사용했습니다.
덕분에 Qwen1.5, Llama3등 새로운 모델이 나왔어도 빠르게 초기 결과를 얻을 수 있었습니다. (조만간 결과를 공개하겠습니다. )
원래 이 블로그를 연재하기 시작할 때까지만 해도 데이터 생성 / 모델 학습 / 모델 평가 pipeline에 대한 자세한 이야기를 공유할 수 있을 것이라 생각했는데 Llama3-instruct라는 엄청난 모델의 공개로 인해 살짝 어긋나 버렸습니다.
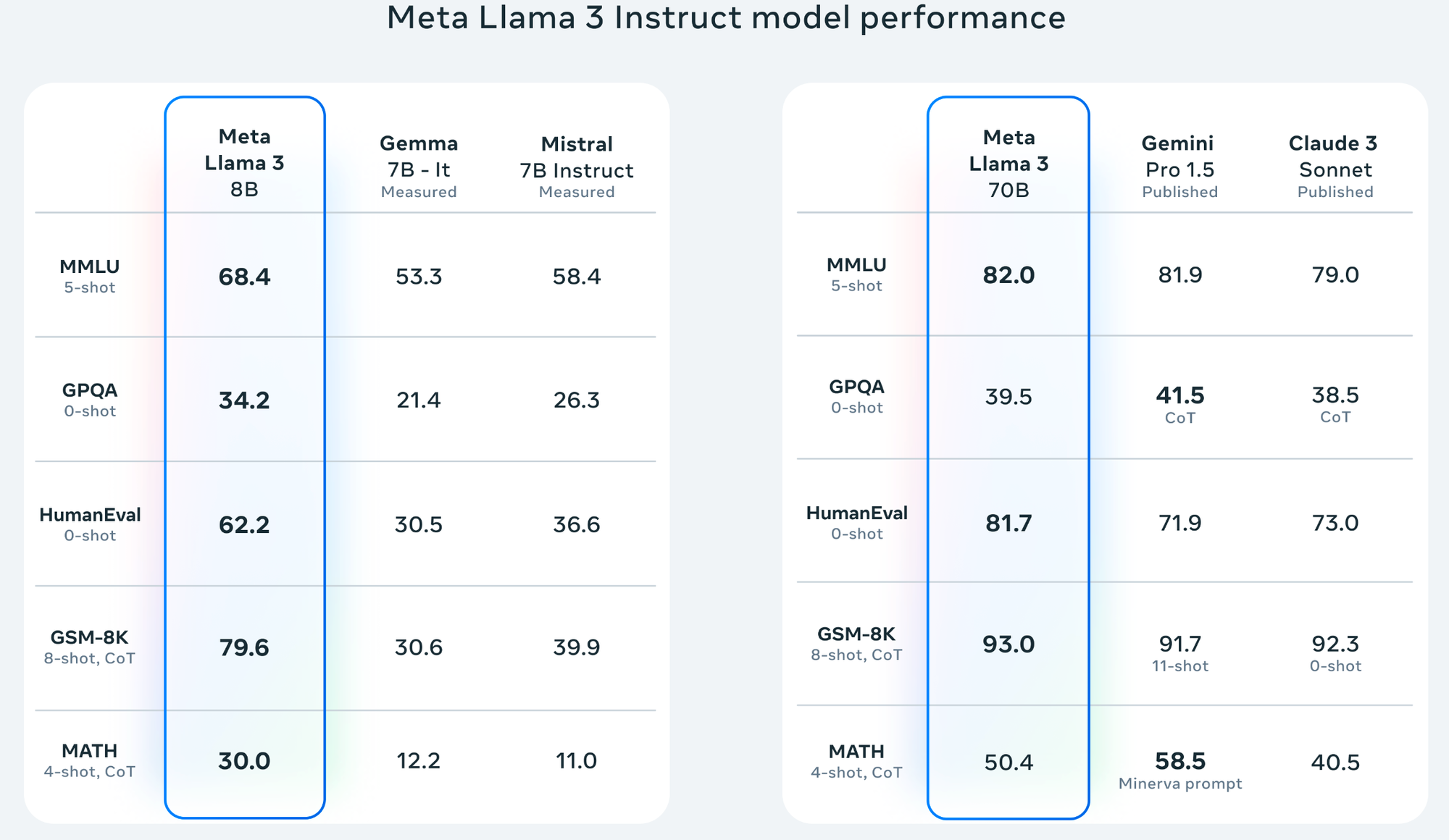
먼저 model이 할 수 있는 일에 대해서 범위를 엄청 늘려잡아야 했습니다.
“오픈소스 LLM의 지시 순응(instruction following) 능력은 전반적으로 실망스러웠지만 fine-tune을 통한 성능개선의 여지는 확실하게 느낄 수 있었습니다. 이를 이용해서 금융 특화 LLM을 만들기로 결정하였습니다.(금융 LLM 시리즈 1편)” 이라는 문장이 더이상 사실이 아니게 되었습니다. 이제 오픈소스 LLM의 Instruction following 능력도 충분히 서비스화 할 수 있을 만큼 강력해졌습니다. 그에 따라 모델의 능력에 대한 기대치도 이를 평가할 평가 데이터도 새로 정의하고 있습니다.
또한 단순히 SFT로 학습시킨다고 성능이 극적으로 오르지도 않았습니다. Llama3는 Llama2와 같은 구조, 같은 크기의 모델에 7배 많은 데이터를 학습시켰습니다. 아직은 섣부른 예측일 수도 있지만 이미 충분히 잘 학습되어있어서 단순한 SFT만으로는 득보다 실이 많았을 수 있습니다. 따라서 여러가지 가능성을 다시 따져보고 있습니다.
블로그가 연재되는 한달 사이만 해도 엄청난 변화가 있는 시대임을 다시 한 번 느끼며 Alpha-F(EEVE)의 제작 후기는 이만 마치도록 하겠습니다. 앞으로 더 좋은 모델과 서비스로 다시 찾아오겠습니다.