[금융 LLM 시리즈 3] 금융 전문 AI를 위한 평가 전략
금융 전문 LLM의 성능은 어떻게 평가해야 할까요? 금융과 금융 문서를 이해하고, 복잡한 추론과 수식에 강해야 하는 LLM을 제대로 비교하고 평가하기 위해서는 정량평가와 정성평가가 모두 필요합니다. 금융 LLM 시리즈 3편, 금융 전문 AI를 위한 평가 전략에서 올거나이즈 AI팀의 고민과 진행과정을 공유합니다.

![[금융 LLM 시리즈 3] 금융 전문 AI를 위한 평가 전략](https://storage.ghost.io/c/e6/c4/e6c4e989-7bf7-45ef-8e98-79671db8ba4c/content/images/size/w2000/2024/05/-----------2024-05-08-------10.47.35.png)
금융 LLM 시리즈는 온프렘 구축이 가능한 오픈소스 모델 중에서 성능 좋은 금융 AI 모델을 만들기 위한 올거나이즈 AI 팀의 고민과 진행 과정을 공유하고 있습니다.
1편은 성능 좋은 금융 전문 LLM의 정의와 평가 방법론에 대해 올거나이즈 신기빈 CAIO가 방향을 제시했습니다.
 Allganize Korea
Allganize Korea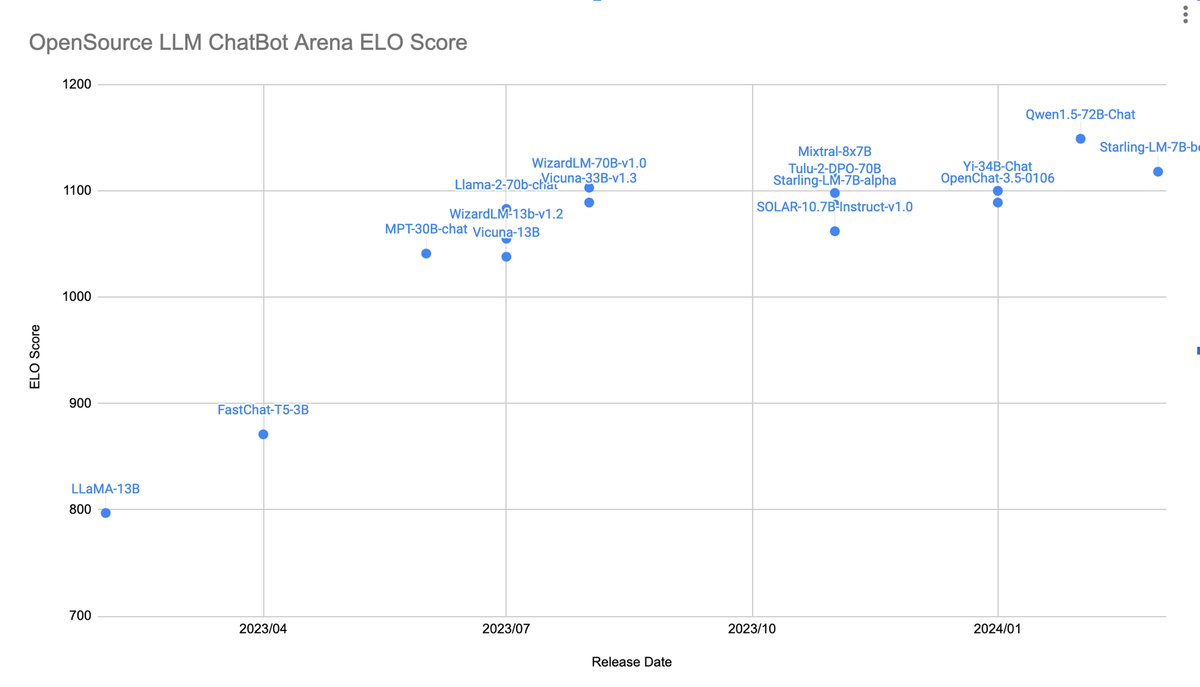
2편은 어떤 학습 방법으로 데이터 셋을 만들어서 금융 LLM의 성능을 평가할 준비를 했는지에 대해 박종헌 AI 엔지니어가 설명했습니다.
Allganize Korea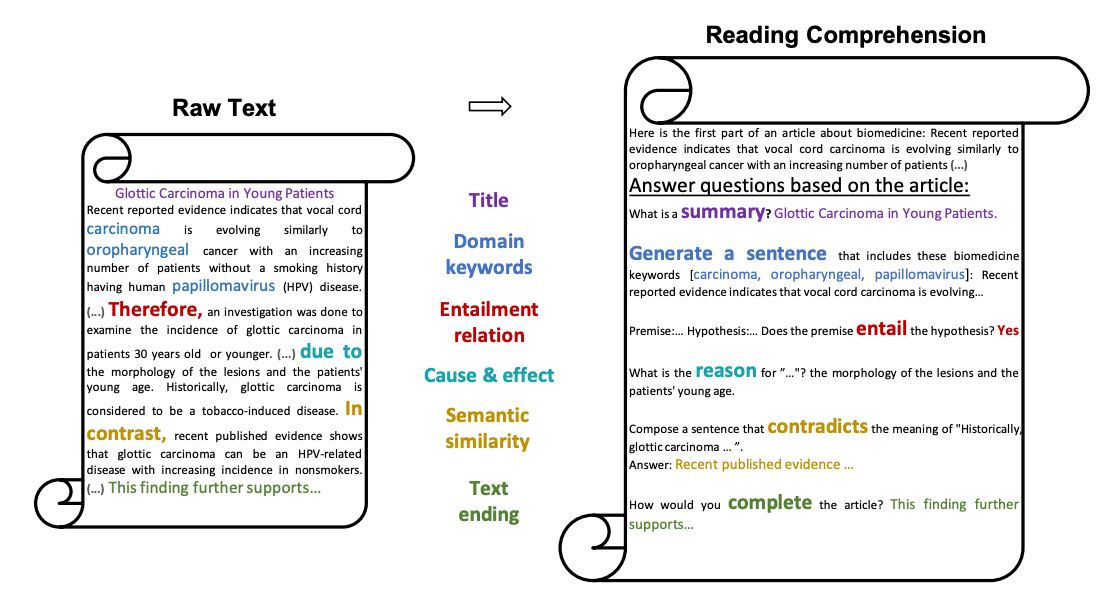
3편은 어떻게 금융 전문 모델들의 성능을 평가했으며, 이 과정에서 왜 정량평가와 정성평가를 모두 사용했는지에 대해 류승우 AI 엔지니어가 자세히 설명하겠습니다.
올거나이즈는 최근 금융 특화 언어모델의 두 번째 버전인 ‘Alpha-F’와 함께 금융 리더보드를 공개하였습니다. 이 모델은 OpenAI 사의 GPT-4, Anthropic 사의 Claude3-시리즈 다음으로 높은 점수를 기록했는데요. 금융리더보드의 결과가 어떠한 방식으로 평가 되었는지에 대해 ‘정량평가’와 ‘정성평가’의 두 가지 측면에서 이야기해보도록 하겠습니다.
정량평가
정량평가를 위한 tool로는 EleutherAI 사의 오픈소스 라이브러리인 lm-evaluation-harness (GitHub - EleutherAI/lm-evaluation-harness: A framework for few-shot evaluation of language models. , 이하 harness )를 사용하였습니다. General 도메인의 다양한 벤치마크들이 이미 정의되어 있고, API 기반 모델 추론, few-shot 등의 편리한 기능을 제공하고 있으며, 지금도 많은 사람들이 contribute 하고 있는 라이브러리이기 때문에 해당 harness를 평가 툴로 선택하였습니다.
분류
‘‘생성형' 언어 모델로 어떻게 ‘분류’ 문제의 성능을 평가할 것인가?' 라는 질문에, 저희는 가장 먼저 acc_contain 이라는 지표를 정의하였습니다. 모델의 답변에 레이블이 포함되어 있다면 이를 정답 처리하는 방식입니다. 하지만, 곧 해당 측정 방식에 문제가 있음을 발견할 수 있었는데, 입력값의 문구를 답변에서 그대로 출력하거나 (예시1), 등장할 수 있는 모든 선택지를 포함하는 답변을 생성(예시2)하는 경우가 빈번히 발생했다는 것입니다. 분명 틀린 답변임에도 불구하고 정답으로 간주하게 되는 것이죠.

그래서 저희는 harness 가 제공하는 multiple_choice 형식을 사용하였습니다. 이 형식은 등장할 수 있는 답변의 후보군 가운데 loglikelihood를 최대화할 수 있는 답변을 최종 답변으로 채택하는 방식입니다. 애초에 다양한 레이블들이 모두 포함되어 있는 문장을 생성할 수 없도록 강제하는 것이죠. 예를 들어, 위에서 언급된 예시에 대해 harness는 다음 세 문장의 Loglikelihood를 측정합니다.

한 예시로, 당사의 Alpha-F 모델에서 각 문장은 약 -0.2458, -1.6201, -5.0995의 loglikelihood를 기록하였고, 이 경우 모델은 ‘긍정’을 정답으로 예측할 것입니다. 이같은 방식으로, ‘감성 분류’ 문제인 fpb-ko, fiqasa-ko뿐만 아니라 객관식 문제의 정답을 선택하는 mmlu-finance-ko 벤치마크의 성능 또한 측정하였습니다.
그런데 OpenAI, Anthropic과 같은 API 기반의 모델은 생성된 텍스트를 반환할 뿐, loglikelihood 수치를 제공하지는 않습니다. 따라서, 위 방식과 동일한 방법으로 분류 성능을 측정할 수 없으며, 모델이 생성한 답변으로부터 바로 분류 성능을 평가해야 합니다. 하지만, 이 방법 역시 앞서 지적한 문제가 동일하게 존재합니다. 한 예로, OpenAI 사의 gpt-4-0125-preview 모델은 감성 분류 문제에 대해 다음과 같은 형식으로 답변합니다. 이 문장은 특정한 긍정적이거나 부정적인 정보, 감정, 또는 평가를 전달하지 않고 있습니다. 따라서 이 문장의 정서는 ‘중립'으로 분석됩니다. 문장은 정보 제공자에 대한 연락처 정보와 회사의 간단한 소개로 구성되어 있으며, 긍정적이거나 부정적인 의견이나 감정을 직접적으로 표현하고 있지 않습니다. 분명 user prompt에서 ‘부정, 긍정 또는 중립 중 하나로 답을 제시하세요’ 라는 지시를 내렸음에도, 말을 듣지 않는 것이죠. 이에 저희는 다음과 같은 system prompt를 추가하였고, 마침내 ‘긍정’, ‘중립’, ‘부정’ 만을 답변으로 얻어낼 수 있었습니다. (당신은 유능한 금융 assistant입니다. 반드시 ‘부정', '긍정', '중립' 중 한 가지 단어로만 답하세요.) API 기반의 LLM들은 대체적으로 instruction following 능력이 뛰어나 이같은 간단한 instruction만으로도 원하는 출력을 얻을 수 있었습니다.
생성
생성 벤치마크는 분류 벤치마크와 달리 답변의 형식을 강제하지 않습니다. ‘분류' 문제가 객관식이라면 ‘생성’ 문제는 주관식인 것이죠. 생성 벤치마크를 평가함에 있어서도 다양한 시행착오들이 있었습니다.
먼저 단답형 문제의 경우입니다. TableQA 벤치마크는 주어진 표를 보고 질문에 대한 답을 생성하는 태스크이며, 태스크 내에는 짧은 답을 요하는 문제가 포함되어 있습니다. 저희는 가장 먼저 acc_contain 및 exact match 를 평가 지표로 사용하였습니다. 각각 모델의 답변 내에 레이블이 포함되어 있거나, 레이블과 정확히 동일한 답변을 생성하였다면 정답으로 간주하는 방식입니다. 하지만, 이 방법에서 또한 저희는 문제를 발견할 수 있었습니다. 예를 들어, 마크다운 형태의 표와 함께 다음과 같은 질문이 주어집니다. Question: 가정보육모제도에서 보육모 한사람당 기본료는 얼마야 . 이 질문에 대한 답변은 150,000 엔 입니다. 이에 대해, 모델이 표에 따르면 가정보육모제도에서 보육모 한 사람당 기본료는 월액 150,000엔입니다. (실제 claude-3-opus-20240229 의 답변) 와 같이 답했다면 이를 정답으로 보아야 할까요? 아니면 오답으로 보아야 할까요? 150,000과 엔 사이에 띄어쓰기가 없기 때문에 acc_contain 의 관점에서 모델의 답은 틀렸고, 단답이 아닌 문장을 생성했기 때문에 em에서도 틀렸습니다. (이게 맞나요...? 이게 최선인가요...?) 문장이 출력되어도 150,000엔과 동일한 액수가 표현되어있다면 ‘정답’이어야 할 것이고, 150,000엔, 150,000 엔, 15만 엔, 15만엔, 십오만 엔 등의 표기법 모두 정답처리 되어야 할 것입니다. 하지만 무수히 많은 코너 케이스를 rule-based로 풀어내기에는 어려움이 많았습니다. 이에, 저희는 LLM을 평가에 사용하기로 하였습니다.
Judging LLM-as-a-Judge with MT-Bench and Chatbot Arena 라는 벤치마크가 소개된 이래로, LLM을 언어 모델 성능 평가에 사용하는 경우가 많아지고 있습니다. 이 논문에 근거하여 저희 또한 리더보드 제작 당시 OpenAI의 최신 언어모델인 openai/gpt-4-0125-preview를 활용하여 언어 모델의 성능을 평가하였습니다. GPT4 사용의 정당성을 확보하기 위해 저희는 다음과 같은 과정을 거쳤습니다.
- 다양한 모델을 사용하여 모든 생성형 벤치마크의 답변을 생성한다.
- 사람이 직접 답변을 평가하여 정답/오답을 표시합니다. ( 이하
HumanEval ) - GPT4를 활용하여 정답/오답을 판별한다. ( 이하
GPTEval) - 사람과 GPT4의 판단을 비교하여 GPT4의 일치율을 계산한다.
HumanEval 과정에서는 한 문항 당 두 명이 평가하였고, 두 명의 의견이 모두 일치하는 경우에만 '일치'로 판단하였습니다. 또한, 두 모델의 결과 모두에 대하여 모든 벤치마크의 HumanEval과 GPTEval 일치도가 90% 이상을 기록하는 프롬프트를 최종 프롬프트로 선정하였습니다. 예를 들어, 정답이 5.58 (.27)인 TableQA 벤치마크의 한 질문에 대해, claude-3-opus-20240229는 다음과 같이 답합니다.

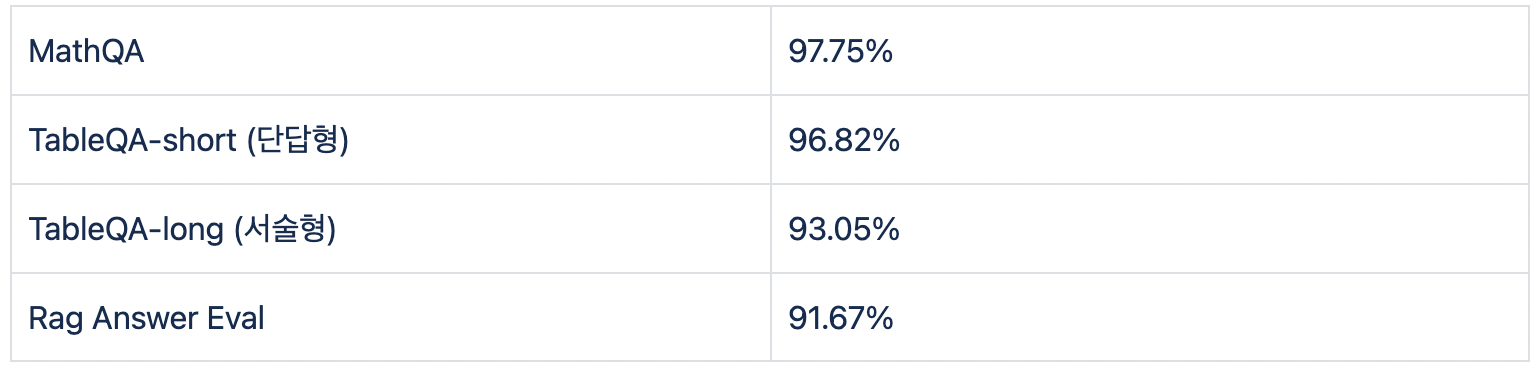
두 명의 annotator 모두가 이 답변을 ‘일치’로 판단하였고, 아래의 프롬프트를 사용한 결과 GPT-4 또한 이 답변을 ‘일치’로 평가하였습니다. 이러한 경우가 HumanEval과 GPT4의 판단이 일치하는 경우이며 아래 프롬프트를 사용하여 Table-QA 벤치마크에서는 약 96.8%의 일치도를 기록하였습니다.
아래 예시는, 단답형 TableQA를 위해 사용한 GPT4 System Prompt입니다.

서술형 생성 문제의 경우 가장 먼저 rouge-score (이하 rouge)를 시도하였습니다. 그러나, '❍', '•', '-' 등의 특수 문자가 정답 내에 사용되는 경우가 빈번하다는 점, 동일한 내용을 담고 있음에도 다른 표현 방식으로 답변을 생성하는 모델들이 존재하는 점 등으로 인하여 rouge는 모델의 성능 지표로서는 적합하지 않다는 결론을 내렸습니다. 이에 따라, 서술형 벤치마크 역시도 GPTEval을 사용하였습니다.
마지막으로, RAG 벤치마크는 모델이 주어진 statements의 내용을 잘 참고하여 질문에 대한 답변을 생성하는지 평가하는 벤치마크입니다. RAGAS 논문 (RAGAS: Automated Evaluation of Retrieval Augmented Generation)의 프롬프트 구성 방식을 따라, 각 statement 별로GPTEval 과정을 거침으로써 약 91.7%의 HumanEval - GPTEval 일치율을 기록하였습니다. 예를 들어, 저금리 상황에서 은행과 보험회사가 겪는 어려움은 무엇인가요? 라는 질문과 저금리 상황에서 은행과 보험회사는 스프레드가 전반적으로 축소되는 경우 금융중개기능의 취약성이 증가하며, 이로 인해 금융투자회사의 신용평가 및 선별 기능이 약화될 수 있습니다 (context 3). 보험회사는 이차역마진이 고착화되어 보험산업의 가치사슬에 변화가 필요하며, 4차 산업혁명으로 인해 보험산업 전체의 변화가 예상되고 있습니다 (context 2). 라는 두 statements가 주어졌을 때, 모델이 생성한 답변에 각 statement의 내용이 포함되어 있는지를 평가합니다.
GPT4에 사용되는 프롬프트 구성에 차이가 있을 뿐, 모든 서술형 벤치마크는 GPTEval 을 평가 지표로 사용하였습니다. 생성형 벤치마크 별 평균 HumanEval - GPTEval 일치율은 다음과 같습니다.
Prompting
‘모델의 Input을 어떻게 구성할 것인가?’ 또한 고려사항 중 하나였습니다. Harness의 가장 베이직한 형태만을 사용한다면 모든 모델에 대해 동일한 프롬프트 템플릿을 적용할 수 있었기 때문이죠. 하지만, 대화 기능을 지원하기 위해 추가적인 템플릿을 추가하여 학습한 모델의 템플릿을 온전히 무시하고, 가장 베이직한 형태의 프롬프트로 모델의 성능을 측정한다는 것은, 분명 모델의 capacity를 온전히 사용하지 못함을 의미합니다. 따라서, 저희는 각 모델이 학습된 프롬프트를 존중하여 모델의 성능을 측정하였습니다.
그러나 현재 harness에는 이러한 템플릿을 ‘자동으로’ 고려해주는 기능이 존재하지 않습니다. 따라서, 처음에는 고정된 형태의 입력 데이터에 대해, process_docs 를 manual하게 수정해주는 방식을 채택했습니다. 예를 들어, process_docs를 아래와 같이 구성하는 것이죠.

그러나, 벤치마크와 고려해야 할 모델의 수가 늘어날수록, 이 작업들을 모두 수작업으로 진행하기에는 어려움과 피로도가 있었습니다. 또한, google/gemma-7b-it 나 OrionStar/Orion-14B-Chat 모델과 같이 챗봇 형태로 학습되었으나, ChatML 형태를 따르지 않는 예외적인 경우도 빈번히 발생하였습니다.
이같은 번거로움을 해결하기 위해 harness 내에 새로운 기능을 추가하였습니다. HuggingFace에 제공되는 모델 중 apply_chat_template 메서드를 사용할 수 있는 instruction-tuned 모델이라면 자동으로 프롬프트 형태를 적용해주는 기능입니다. 예를 들어, process_docs에 {{template}} 이라고만 명시 해준다면, 모델은 자동으로 ChatML 형태의 입력값을 받게 됩니다. 이를 통해, 모델마다 최적의 프롬프트 형태를 갖출 수 있게 되었고, 이 프롬프트로 모델들의 벤치마크 성능을 측정하였습니다.
물론, 가장 Basic한 형태의 템플릿으로 모든 모델의 성능을 측정할 수는 있습니다. 그러나, 공평한 상황에서 각 모델이 최고의 성능을 낼 수 있는 환경을 조성하는 것이 중요하다고 생각하였고, 모든 벤치마크의 평가는 위와 같은 방식으로 이루어졌습니다. (물론, 언급한 방식을 통해 작성한 프롬프트가 최적의 프롬프트가 아닐 수 있습니다. 좀 더 좋은 프롬프트가 있다면, 해당 프롬프트를 사용하여 더 공정한 평가를 진행할 수 있을 것입니다.) 분류 문제의 경우에만 원활한 Loglikehood 측정을 위해 예외적으로 베이직한 형태를 따랐습니다. 예를 들어, MathQA 벤치마크의 경우 당사의 Alpha-F는 아래와 같은 형식의 텍스트를 모델의 입력값으로 받게 됩니다.

정성평가
모델의 성능을 하나의 실수값으로 나타낼 수 있다는 점에서 정량평가는 분명 가치가 있습니다. 그러나, ‘이 수치가 정말 모델을 평가할 수 있는가.’에 대한 우려는 항상 제기돼 왔고, 실제로 자연어처리 연구 논문에서도 Human Evaluation을 진행하는 것이 필수로 여겨지고 있습니다. 이에 저희 또한, 단순히 숫자로 모델의 성능을 판단하기 보다, 실제로 정성 평가를 통해 모델이 사용자 친화적인 답변을 생성하고 있는지 판단하려 하였습니다.
현재 Chatbot Arena (https://chat.lmsys.org/) 는 동일한 질문에 대한 두 모델의 답변 중 어떤 모델의 답변이 더 우수한지를 평가하는 방식으로 모델을 평가하며, 투표의 표본이 쌓일수록 정성평가의 신뢰도는 올라갑니다. 이에, 올거나이즈 또한 이와 동일한 방식으로 금융특화 리더보드 (금융 LLM Leaderboard )를 만들었으며, 정량 평가 결과를 공유함과 동시에 사용자들의 평가 정보를 반영하고 있습니다.


4편에서는 학습과 해석에 대해 공유 드리겠습니다. 모델 학습시 고려해야 할 점, 정량 평가와 정성 평가가 차이나는 이유에 대한 고찰 등을 담아낼 예정입니다.
온프렘 금융 LLM 구축 방법 및 관련해 궁금한 점이 있으시다면 언제든지 올거나이즈에 문의 남겨 주세요.
