실시간 서비스를 위한 Cross-Encoder 경량화 시도와 엔지니어링을 통한 최적화

* 실시간 서비스를 위한 Cross-Encoder 경량화 시도에 대해 올거나이즈 RAG팀의 조한준 엔지니어님이 설명해 드립니다.
1. 서론: Cross-Encoder와 실시간 검색 시스템의 과제
1.1 배경
Reranking은 검색 시스템에서 검색 결과의 품질을 결정짓는 핵심 과정으로, 최종 사용자 경험에 큰 영향을 미칩니다. 이 중에서도 Cross-Encoder는 쿼리와 문서 간의 상호작용을 정교하게 모델링하여, 기존 검색 모델(BM25, Bi-Encoder)보다 우수한 정확도를 제공합니다.
Cross-Encoder는 검색 엔진, 추천 시스템, RAG (Retrieval-Augmented Generation) 등 다양한 환경에서 최고 성능(SOTA)을 달성하며, 정보 검색 및 추천 품질 향상에 크게 기여하고 있습니다. 특히, 복잡한 검색 쿼리나 높은 문맥적 이해를 요구하는 작업에서는 Cross-Encoder의 중요성이 더욱 부각됩니다.
1.2 필요성
하지만 Cross-Encoder의 구조적 특성은 실시간 검색 시스템에서의 큰 과제로 작용합니다.
- 높은 연산량
- Cross-Encoder는 대규모 데이터에서 쿼리-문서 간 상호작용을 계산하며, 높은 연산량을 요구합니다. 이는 실시간 검색 환경에서 응답 시간 지연의 주요 원인이 됩니다.
- Cross-Encoder는 대규모 데이터에서 쿼리-문서 간 상호작용을 계산하며, 높은 연산량을 요구합니다. 이는 실시간 검색 환경에서 응답 시간 지연의 주요 원인이 됩니다.
- 계산 비용 증가
- Reranking은 RAG 프로세스에서 일부 단계에 불과한데, 이 단계에서 과도한 자원 소비는 전체 시스템의 성능 저하로 이어질 수 있습니다.
- Reranking은 RAG 프로세스에서 일부 단계에 불과한데, 이 단계에서 과도한 자원 소비는 전체 시스템의 성능 저하로 이어질 수 있습니다.
- 응답 시간의 중요성
- 실시간 검색 시스템에서 응답 시간은 사용자 경험의 핵심 지표로 작용합니다. 작은 지연이라도 사용자가 느끼는 품질 저하로 이어질 수 있습니다.
- 실시간 검색 시스템에서 응답 시간은 사용자 경험의 핵심 지표로 작용합니다. 작은 지연이라도 사용자가 느끼는 품질 저하로 이어질 수 있습니다.
이를 해결하기 위해 모델 경량화는 필수적입니다.
대표적인 경량화 기법으로는 Pruning, Distillation, Quantization이 있으며, 특히 Quantization은 속도와 효율성을 크게 개선할 수 있는 강력한 도구로 주목받고 있습니다. 이러한 경량화 작업은 Reranking 단계의 부담을 줄이고, 실시간 검색 시스템의 확장성과 효율성을 크게 향상시킬 수 있습니다.
또한, 딥러닝 모델을 실제 서비스에 적용하기 위해서는 다양한 엔지니어링 요소를 고려해야 합니다. 하드웨어 선택, 서빙 플랫폼 선택, 태스크에 맞는 최적화 등 여러가지 요소를 고려해야 합니다.
Quantization과 다양한 엔지니어링 요소를 결합할 경우, 최대 10배 이상의 속도 향상이 가능합니다.
2. Cross-Encoder를 실제 서비스에 적용할 때 문제점
2.1 Cross-Encoder의 작동 원리
Transformer 구조 기반
Cross-Encoder는 Transformer 기반 언어 모델(BERT, RoBERTa 등)을 활용하여 쿼리와 문서 간의 관계를 정교하게 모델링합니다.
- 쿼리와 문서를 단일 입력 시퀀스로 병합하여 두 입력 간의 문맥적 상호작용을 평가합니다.
입력 처리 방식
- 입력 형식:
[CLS] query [SEP] document [SEP]형태로 쿼리와 문서를 결합하여 모델에 전달합니다. [CLS]토큰의 출력 임베딩을 활용해 쿼리-문서 간의 최종 Relevance 점수를 계산합니다.- 이 과정에서 쿼리와 문서의 문맥적 의미를 종합적으로 고려하여 높은 정확도를 달성합니다.
기능적 장점
- 쿼리와 문서 간의 상호작용을 직접 모델링하므로 기존 독립적 인코딩 방식(Bi-Encoder)보다 정밀한 평가가 가능합니다.
- 복잡한 쿼리와 문서의 문맥적 관계를 파악하는 데 강점을 가지며, 검색 및 추천 시스템에서 최고 성능(SOTA)을 자랑합니다.
2.2 Cross-Encoder의 구조적 특성과 문제점
모든 입력 쌍에 대한 연산 수행
- Cross-Encoder는 쿼리 하나당 여러 문서를 쿼리와 함께 언어 모델에 입력하여 결과를 산출합니다.
- 입력 쌍의 수가 많아질수록 계산량이 선형적으로 증가하여 연산 효율성이 낮아집니다.
다층 Transformer 연산의 복잡도
- Cross-Encoder는 일반적으로 수십 개의 Transformer 계층(예: BERT-Base는 12 Layer, BERT-Large는 24 Layer)을 포함하여 높은 연산 비용을 요구합니다.
- Self-Attention 연산의 복잡도는 입력 길이에 대해 O(n²)로 증가하여 긴 문서 처리 시 메모리 사용량과 추론 시간이 기하급수적으로 증가합니다.
추론 속도와 병목현상
- 실시간 시스템에서 다수의 복잡한 연산을 처리해야 하므로 Cross-Encoder의 느린 추론 속도와 과도한 메모리 사용량은 서비스 구현 시 큰 장애 요소로 작용합니다.
2.3 Cross-Encoder 문제 해결책: 경량화 기법
Pruning
- Pruning은 모델의 가중치나 뉴런 등 중요도가 낮은 요소를 제거하여 계산량을 줄이는 기법입니다.
- Attention Head, 특정 Layer, 또는 Feed Forward Network를 대상으로 Pruning을 적용할 수 있습니다.
- 그러나 특정 하드웨어 가속기가 필요하며, 상황에 따라 연산 오버헤드가 발생해 성능이 저하될 수 있습니다.
Distillation
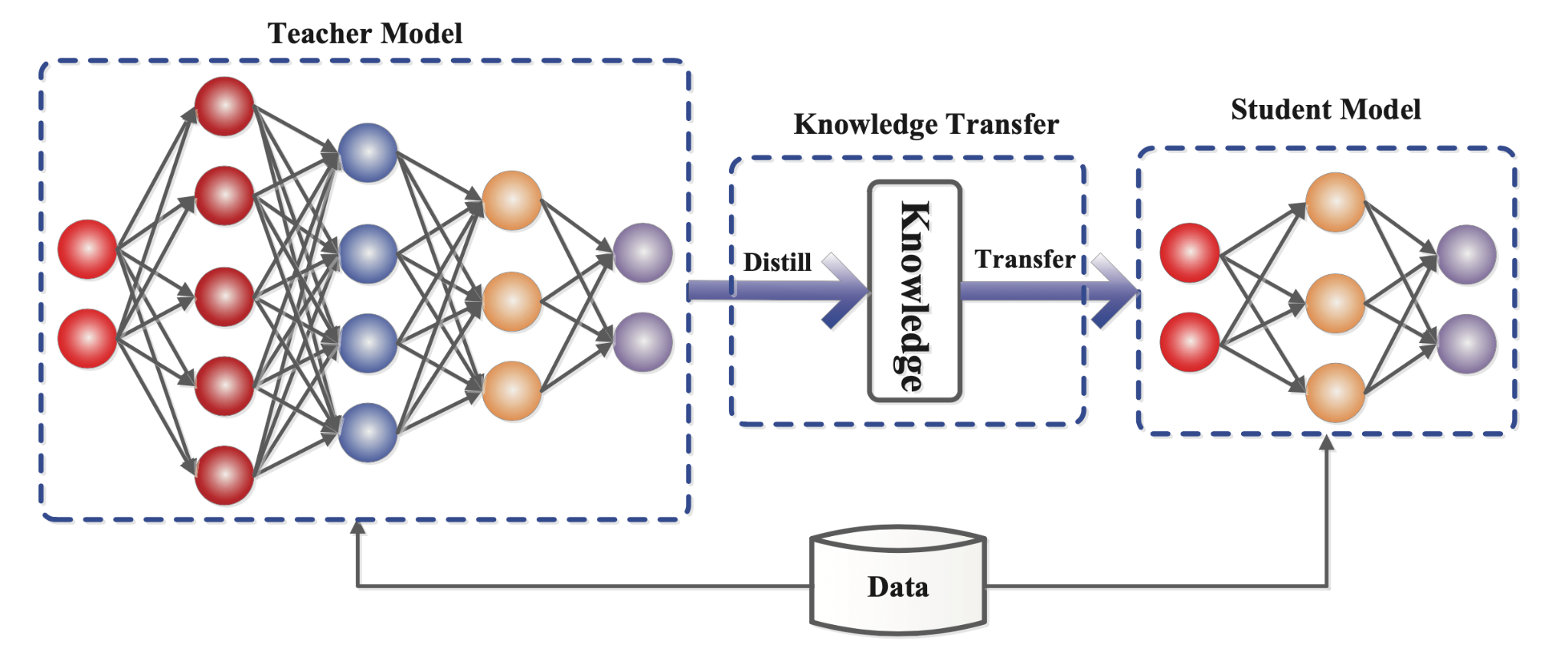
- Distillation은 대규모 모델(Teacher)의 지식을 소규모 모델(Student)로 전이하여 경량화하는 기법입니다.
- Teacher 모델이 생성한 점수 분포나 중간 레이어 표현을 Student가 학습하도록 설계해 정확도를 유지합니다.
- 다만 학습 과정에서 추가 비용이 요구되고, Student 모델의 성능이 Teacher에 비해 감소하는 문제가 있습니다.
Quantization
- Quantization은 모델의 가중치와 활성화 값을 낮은 정밀도(FP16, INT8 등)로 변환하여 연산 효율성을 높이는 기법입니다.
- Post-Training Quantization(PTQ)을 통해 정확도 손실을 최소화하며, 속도와 메모리 사용량을 크게 개선할 수 있습니다.
- 실시간 검색 시스템에서 요구되는 낮은 지연 시간과 자원 효율성을 달성하기 위해 Quantization은 매우 효과적이며, 실제 서비스에서도 이 기법을 채택하고 있습니다.
3. Pruning: 가중치 및 구조 축소
3.1 개념과 원리
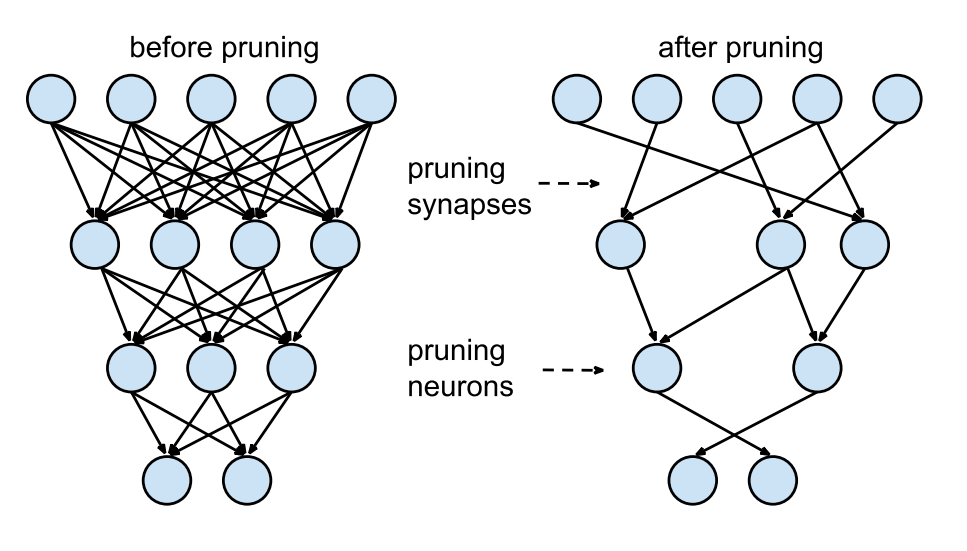
Pruning은 모델에서 중요도가 낮은 요소를 제거하여 연산량을 줄이고, 모델 크기를 축소하는 기법입니다.
- Transformer 모델에서는 특정 Layer, Attention Head, 또는 Feed Forward Network(FFN)를 대상으로 Pruning을 수행할 수 있습니다.
- Pruning의 목표는 모델 성능 손실을 최소화하면서도 계산 효율성을 극대화하는 데 있습니다.
3.2 주요 유형
Unstructured Pruning
- 개별 가중치(Weight)를 기준으로 중요도가 낮은 값을 제거하는 방식입니다.
예: 절대값이 작은 가중치를 0으로 설정하여 연산을 단순화. - 자유도가 높지만, Sparse Matrix 연산을 요구하므로 하드웨어 의존도가 크고 사용 조건이 까다롭습니다.
Structured Pruning
- Neuron, Attention Head 등 모델의 구조적 요소를 단위로 제거하는 방식입니다.
- Dense Matrix 연산을 유지하므로 하드웨어 효율성이 높습니다.
- 그러나 구조적 변경으로 인해 성능 손실 가능성이 있습니다.
3.3 장점
연산량 감소
- 모델 크기와 연산량을 줄여 추론 속도를 개선합니다.
- 특히 대규모 모델에서 과도한 자원 소모를 완화하는 데 효과적입니다.
메모리 사용량 감소
- 불필요한 요소를 제거하여 모델의 메모리 사용량을 줄일 수 있습니다.
3.4 한계
성능 손실 가능성
- 중요도가 높은 뉴런이나 가중치를 제거할 경우, 모델의 정확도가 크게 저하될 위험이 있습니다.
Sparse Matrix 연산의 제약
- Unstructured Pruning은 Sparse Matrix 계산을 가속화할 수 있는 하드웨어가 필요합니다.
- Sparsity(희소성) 비율이 낮을 경우 Sparse Matrix 관리의 오버헤드로 인해 성능이 오히려 저하될 수 있습니다.
- 일반적으로 Sparsity가 70~80% 이상이어야 속도 향상이 기대되지만, 과도한 Pruning은 성능 감소를 초래할 수 있습니다.
3.5 서비스에 적용하는데 한계점
Structured Pruning
- 모델의 구조를 변경하므로 성능 하락 가능성이 높습니다.
Unstructured Pruning
- Sparse Matrix 연산에 최적화된 하드웨어가 필요합니다.
- FPGA 또는 NVIDIA A100, H100과 같은 고급 GPU에서 효과적입니다.
- 하지만 H100의 경우, AWS 연간 기준으로는 약 18억 원 이상 소요됩니다.
- 이는 실시간 서비스에 대규모로 적용하기에는 매우 비효율적입니다.
Sparse Matrix의 추가 오버헤드
- Pruning으로 일부 가중치를 0으로 만들어도 Sparse Matrix 연산이 효과적으로 이루어지려면 압축 형식(예: CSR, CSC)이 필요합니다.
- Sparsity 비율이 50% 미만인 경우, Sparse Matrix 관리로 인한 오버헤드로 인해 성능이 오히려 저하될 가능성이 있습니다.
Pruning은 특정 조건에서는 효과적일 수 있지만, 서비스에 적용할 때는 하드웨어 제약과 오버헤드 문제를 면밀히 검토해야 합니다.
4. Distillation: 지식 전이를 통한 경량화
4.1 개념과 원리
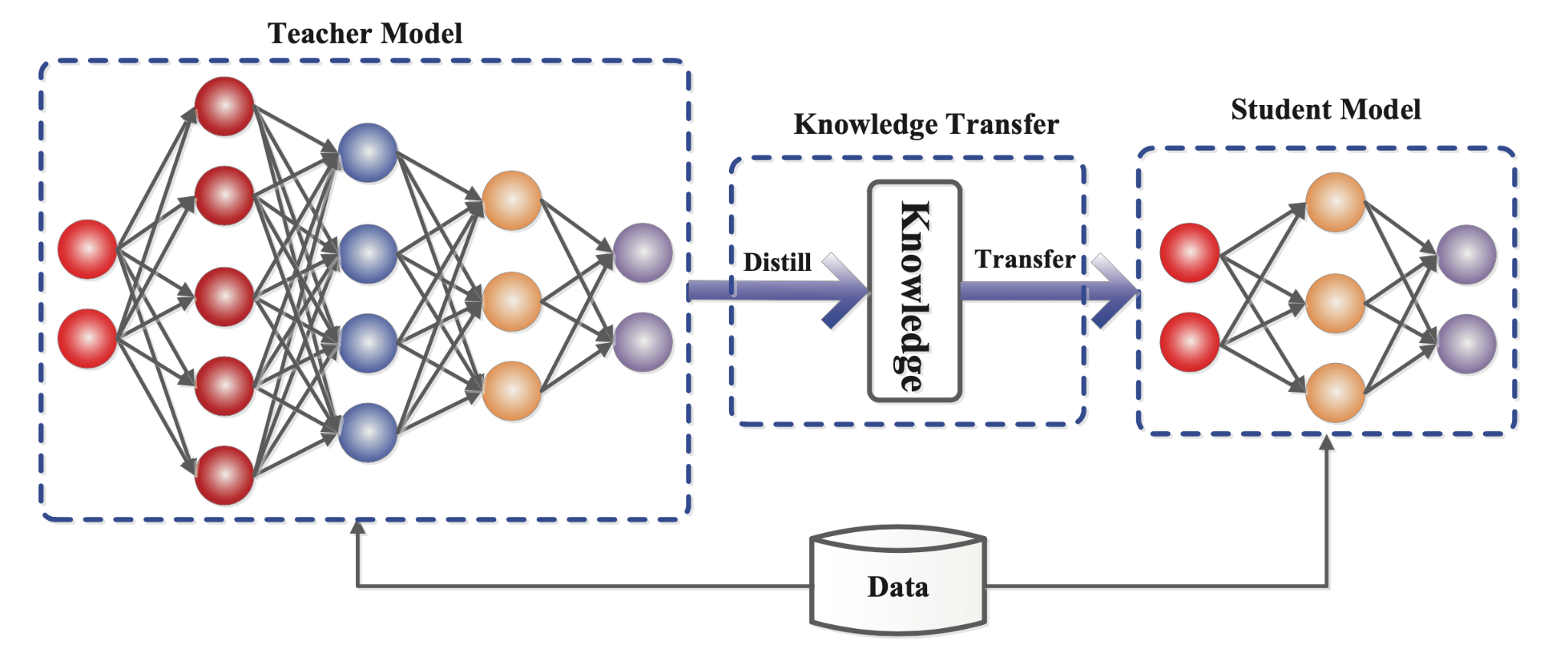
Distillation은 대규모 모델(Teacher)의 지식을 소규모 모델(Student)로 전이하여 모델 크기를 줄이고, 정확도를 유지하면서도 계산량을 대폭 줄이는 기법입니다.
- Teacher 모델이 생성한 출력(Soft Label)이나 중간 표현을 Student 모델이 학습하도록 하여, Teacher와 유사한 성능을 갖는 경량 모델을 구현합니다.
- Hard Label(실제 데이터의 레이블) 대신 Soft Label을 사용하는 이유는, Soft Label이 Teacher 모델의 출력 정보를 활용하여 더 다양한 학습이 가능하기 때문입니다.

- Cross-Encoder에서는 Teacher 모델이 생성한 Relevance 점수나 Attention 분포를 Student 모델이 학습하여 추론 효율성을 높이는 방식으로 활용됩니다.
4.2 주요 유형
Output-Level Distillation
- Teacher 모델의 최종 출력(Soft Label)을 Student 모델이 학습하도록 하는 방식입니다.
- 예: Teacher 모델이 생성한 점수 분포를 학습하여 Relevance 계산 과정을 간소화합니다.
Intermediate Representation Distillation
- Teacher 모델의 중간 Layer 정보(예: Attention Score, Hidden State)를 Student 모델이 학습하는 방식입니다.
- Cross-Encoder에서는 Attention Map이나 Hidden Representation을 Student 모델에 전달하여 Teacher 모델의 정보 표현력을 효율적으로 전달합니다.
- Cross-Encoder에서는 Attention Map이나 Hidden Representation을 Student 모델에 전달하여 Teacher 모델의 정보 표현력을 효율적으로 전달합니다.
Task-Specific Distillation
- 특정 작업에서 Teacher와 Student 간의 Task Performance를 맞추는 방식으로, 특정 작업에 최적화된 경량 모델을 생성합니다.
4.3 장점
모델 경량화
- Teacher 모델 대비 계산량과 메모리 사용량이 크게 줄어든 Student 모델을 생성할 수 있습니다.
범용성
- Teacher 모델이 다양한 작업에서 생성한 지식을 전이할 수 있어, 여러 작업에 활용할 수 있습니다.
성능 유지
- Teacher 모델의 지식을 효과적으로 전이하여, Student 모델이 작은 크기에도 불구하고 높은 성능을 유지합니다.
4.4 한계
복잡한 지식 전이의 한계
- Teacher 모델이 학습한 고차원적 표현을 Student 모델이 완전히 습득하지 못할 수 있습니다.
최적화의 어려움
- Student 모델이 Teacher 모델의 예측 분포를 정확히 모방하지 못하는 경우가 많으며, 이는 추가 학습 시간과 비용을 요구합니다.
- 태스크 난이도가 높을수록 이러한 현상이 두드러집니다.
데이터 의존성
- Distillation 과정에서 사용하는 데이터의 특성에 따라 Student 모델의 성능이 크게 좌우됩니다.
- Teacher 모델이 다양한 데이터를 학습한 경우, Student 모델은 제한된 데이터셋만 학습해 성능 격차가 발생할 수 있습니다.
4.5 서비스에 적용하는데 한계점
- 학습 비용과 시간 문제
- Distillation을 통해 Student 모델이 Teacher 모델을 모방하려면 수천~수만 시간의 학습이 필요하다는 연구 결과도 있습니다.
- 해당 연구는 상대적으로 단순한 이미지 데이터를 기반으로 한 결과이며, 복잡한 자연어 처리(NLP)에서는 학습 자원이 더 많이 요구될 수 도 있습니다.
- 도메인 다양성 문제
- 당사는 3개국(한국, 미국, 일본)의 다양한 도메인에서 서비스를 운영 중입니다.
- Distillation은 특정 데이터에만 Student 모델을 최적화시킬 가능성이 있어, 전체 서비스 품질 저하로 이어질 수 있습니다.
Distillation은 강력한 경량화 기법이지만, 학습 시간과 도메인 다양성 문제를 해결하기 위한 추가적인 고려가 필요합니다.
5. Quantization: 정밀도 축소를 통한 경량화
5.1 개념과 원리
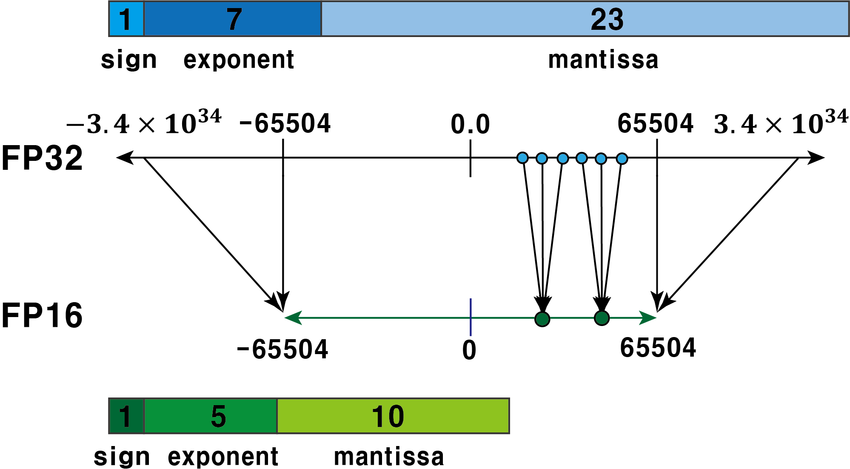
Quantization은 딥러닝 모델의 가중치와 활성화 값을 낮은 정밀도 형식으로 변환하여 계산 효율성을 높이고 메모리 사용량을 줄이는 기법입니다.
- FP32로 표현된 숫자를 FP16이나 INT로 변환하여 연산량과 메모리 사용량을 줄일 수 있습니다.
- 대규모 언어 모델에서 Quantization은 연산 병목을 완화하고 실시간 검색 시스템의 요구를 충족하는 데 유용합니다.
5.2 주요 유형
Post-Training Quantization (PTQ)
- 학습된 모델의 가중치와 활성화 값을 낮은 정밀도로 변환하는 방식입니다.
- 추가 학습 없이도 빠르게 적용 가능하며, FP16 변환으로 성능 손실을 최소화하고 연산 효율을 높일 수 있습니다.
Dynamic Quantization
- 추론 시점에서 정밀도를 동적으로 낮춰 연산을 수행하는 방식입니다.
- CPU 환경에서만 동작하며, GPU와 같은 가속기에서는 비효율적일 수 있습니다.
5.3 장점
추론 속도 개선
- 낮은 정밀도를 통해 계산량을 줄이고, 하드웨어 가속기를 더 효율적으로 활용할 수 있습니다.
- 예: FP16 연산은 FP32 대비 2~4배의 속도 개선이 가능합니다.
- Cross-Encoder의 연산 병목을 줄여 실시간 검색 시스템의 응답 시간을 단축할 수 있습니다.
메모리 사용량 감소
- FP16으로 변환 시 메모리 요구량이 절반 이하로 감소합니다.
- 이는 서비스의 확장성 측면에서 큰 이점을 제공합니다.
5.4 Allganize 서비스에서 Quantization 사용 사례
Allganize는 Cross-Encoder에서 Post-Training Quantization(PTQ)을 활용하여 FP32 가중치와 활성화 값을 FP16으로 변환해 추론 속도를 크게 개선했습니다.
- FP16 PTQ는 추가 학습 없이 간단히 구현 가능하며, GPU 환경에서 메모리 사용량 절감과 연산 속도 향상에 적합합니다.
- PTQ는 연산 효율성을 극대화하며, 실시간 검색 시스템의 성능 요구를 충족하는 효과적인 방법으로 평가받고 있습니다.
5.5 Quantization이 딥러닝에서 잘 작동하는 이유
Quantization이 효과적인 이유는 딥러닝의 근본적 설계와 학습 특성에 기인하며, 다음과 같이 설명됩니다:
- 딥러닝 모델의 근사적 특성
- 딥러닝 모델은 입력과 출력 간의 관계를 대략적으로 학습하며, 미세한 수치적 손실은 모델 성능에 큰 영향을 미치지 않습니다.
- 딥러닝 모델은 입력과 출력 간의 관계를 대략적으로 학습하며, 미세한 수치적 손실은 모델 성능에 큰 영향을 미치지 않습니다.
- 데이터의 불확실성과 노이즈 내성
- 학습 데이터가 불완전하고 노이즈를 포함하더라도, 딥러닝 모델은 자연스럽게 노이즈에 강인한 특성을 갖습니다.
- Quantization으로 인한 미세한 수치적 왜곡은 노이즈처럼 처리되어 성능 저하를 최소화합니다.
- 과잉 표현력(Overparameterization)
- 딥러닝 모델은 종종 필요한 것보다 많은 가중치를 가지며, 가중치의 작은 변화는 성능에 큰 영향을 미치지 않습니다.
- 딥러닝 모델은 종종 필요한 것보다 많은 가중치를 가지며, 가중치의 작은 변화는 성능에 큰 영향을 미치지 않습니다.
- 활성화 함수와 비선형성
- ReLU, GeLU와 같은 활성화 함수는 비선형성을 도입해 일부 수치적 변동을 출력에 반영하지 않습니다.
- 예: ReLU는 음수를 0으로 변환하므로 Quantization으로 인한 음수 변동은 무시됩니다.
Quantization은 이러한 특성을 활용하여 모델 경량화와 실시간 서비스의 효율성을 극대화할 수 있습니다.
6. 실시간 서비스 제공을 위한 엔지니어링 요소
실시간 검색 시스템에서 Cross-Encoder 기반 Reranking을 성공적으로 배포하기 위해서는 단순히 모델 경량화 기술만으로는 부족합니다.
모델 서빙, 하드웨어 최적화, 데이터 전송 효율화 등 다양한 엔지니어링 요소를 함께 고려해야 합니다.
6.1 하드웨어 선택: L4 GPU
효율적인 성능
- NVIDIA L4 GPU는 최신 Ada Lovelace 아키텍처 기반으로 설계되어 준수한 연산 능력을 제공합니다.
- 딥러닝 모델의 추론시간에서 많은 비중을 차지하는 것은 CPU와 GPU 사이의 데이터 전송입니다.
- L4는 PCIe 4.0 지원으로 데이터 전송 속도가 PCIe 3.0 대비 2배 증가하여 CPU와 GPU 간 데이터 전송 병목현상을 완화합니다.
비용 효율성
- A100과 같은 고성능 GPU는 뛰어난 연산력을 제공하지만 높은 비용으로 인해 상업적 실시간 서비스에는 부적절합니다.
- L4는 성능이 크게 향상되면서도 비용 부담이 적어 최적의 선택이 됩니다.
6.2 Serving Platform: Triton Server
다양한 프레임워크 통합
- Triton Server는 TensorFlow, PyTorch, ONNX 등 다양한 프레임워크를 단일 플랫폼에서 통합 운영할 수 있도록 지원합니다.
- 이를 통해 모델 관리 및 배포의 복잡성을 줄이고 운영 효율성을 높입니다.
동적 배치 (Dynamic Batching)
- 다수의 요청을 병합하여 GPU 활용도를 극대화하며, 실시간 응답 속도를 유지합니다.
확장성과 유연성
- Docker, Kubernetes와 통합하여 서비스 확장성과 유연성을 확보하며, 예측 부하에 따라 자원을 동적으로 조정 가능합니다.
6.3 Dynamic Padding을 통한 체감 속도 향상
문제 정의
- 딥러닝 모델은 고정된 크기의 입력만 허용할 경우, 작은 입력 데이터도 최대 입력 크기만큼 계산해야 하는 비효율이 발생합니다.
- 예: 최대 입력 토큰 수가 4096일 때, 100 토큰 입력에도 4096 토큰 만큼 연산 수행.
- 예: 최대 입력 토큰 수가 4096일 때, 100 토큰 입력에도 4096 토큰 만큼 연산 수행.
해결 방법
- Dynamic Padding을 도입하여, Triton Server에서 다양한 크기의 입력도 받을 수 있도록 최적화합니다.
- 입력 크기에 맞게 적절한 연산만 수행하도록 개선.
- 적용 후, 체감 응답 속도가 평균 20~30배 향상되었습니다.
6.4 Quantization
FP16 Post-Training Quantization
- FP32에서 FP16으로 정밀도를 낮춰 연산량과 메모리 사용량을 줄이며, 추론 속도를 크게 개선했습니다.
- 특히, L4 GPU에서 FP16 연산이 최적화되어 효율성이 극대화됩니다.
6.5 최적화 결과
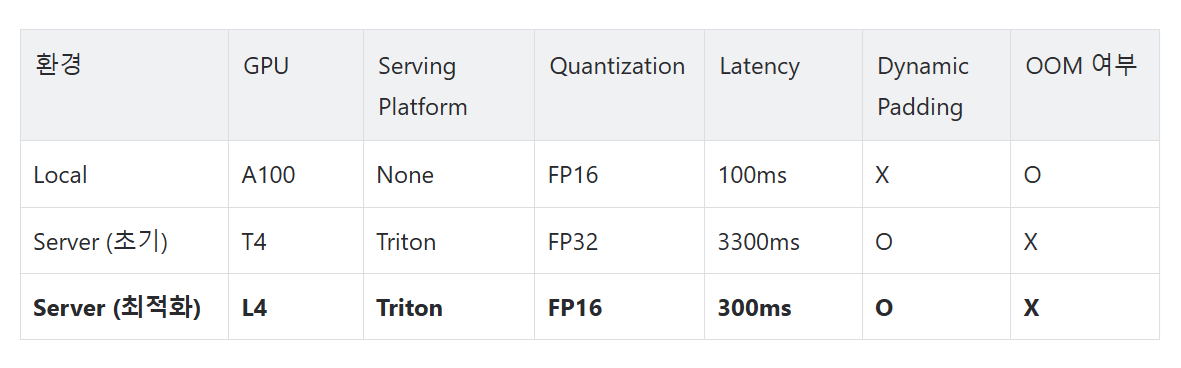
최적화 결과 요약
성능 개선
- 하드웨어(L4), 서빙 플랫폼(Triton), Dynamic Padding, Quantization 등 다양한 요소를 최적화한 결과, 전체 응답 속도가 10배 이상 개선되었으며, 체감 속도는 20~30배 향상되었습니다.
비용 효율성
- A100 같은 고성능 GPU 대비 낮은 비용으로 근접한 수준의 실시간 성능을 달성했습니다.
사용자 만족도
- 최적화된 검색 응답 속도와 모델 정확도로 사용자 만족도가 크게 향상되었습니다.
7. 결론
Cross-Encoder 기반 Reranking은 검색 시스템에서 높은 정확도를 제공하며, 복잡한 문맥적 상호작용을 모델링하는 데 강력한 도구로 자리 잡고 있습니다. 그러나 이러한 모델은 높은 연산 비용과 메모리 사용량으로 인해 실시간 검색 시스템에서 병목현상의 주요 원인이 될 수 있습니다. 이를 해결하기 위해 Pruning, Distillation, Quantization과 같은 경량화 기법과 다양한 엔지니어링 최적화가 도입되었으며, 각각의 기법은 고유한 장점과 한계를 가지고 있습니다.
Allganize는 경량화뿐만 아니라, 하드웨어 최적화(L4 GPU), 서빙 플랫폼 최적화(Triton Server), Dynamic Padding과 같은 엔지니어링 최적화를 도입하여 실시간 검색 시스템의 성능을 획기적으로 개선했습니다. 이러한 최적화를 통해 전체 응답 속도가 10배 이상 향상되었으며, Dynamic Padding으로 체감 속도는 최대 20~30배까지 개선되었습니다.
Allganize는 안정적이고 빠른 서비스 제공을 위해 지속적으로 기술 개발을 이어가고 있습니다. 앞으로는 INT Quantization 및 Embedding 모델 최적화와 같은 최신 기술을 지속적으로 연구 및 도입할 계획입니다. 특히, Embedding 모델에 대한 Quantization은 현재 지원이 열악하기 때문에, TensorRT 및 CUDA 기반의 경량화 기술을 자체적으로 개발하여 더 낮은 비용으로 높은 효율성을 제공하고자 합니다.
이러한 혁신은 실시간 검색 시스템의 경쟁력을 강화하며, 사용자 경험을 더욱 향상시키는 기반이 될 것으로 기대합니다.