LLM 성능 평가 자동화, 2시간⮕10분 단축 노하우
쏟아지는 LLM, 성능 평가 어떻게 하고 계세요? 올거나이즈는 자동 성능 평가를 통해 2시간 걸리던 검증을 10분으로 단축했습니다. LLM 성능 평가 개념과 필요성, LLM Eval, 오차율을 낮추는 방법까지 올거나이즈의 노하우를 공개합니다.


수많은 거대언어모델(LLM)이 등장하면서 성능이 뛰어나다고 여러가지 평가 수치를 내놓는 경우가 많은데요. 기업용 AI 프로젝트에서도 LLM 성능 평가는 무척 중요합니다. 기업 고객이 원하는 것은 수많은 내부 문서와 데이터에서 정확한 답을 찾는 것인데, 기업에 가장 적합한 LLM이 무엇인지 찾는 데만도 시간이 오래 걸리게 됩니다. 올거나이즈는 기업을 위해 최적화된 LLM을 제공하고 있는데, 이를 객관적으로 증명하기 위한 성능 평가 또한 자동화하고 있습니다.
2시간 동안 검증하던 성능 평가를 자동화해 10분만에 가능하게 한 LLM 성능 평가 자동화 노하우에 대해 올거나이즈 RAG팀 이정훈 팀장이 공유합니다.
1. LLM 성능 평가의 개념과 필요성
최근 OpenAI 및 Claude 같은 생성형 모델이 발전하며, 답변 성능 평가 작업을 자주하게 됩니다. 올거나이즈는 여러 고객사의 PoC를 동시에 진행하고 있기 때문에, 성능 평가 작업이 빈번합니다. 답변의 정답 여부를 체크하는 것은 많은 시간과 인력이 필요합니다. 만약 성능 평가를 자동화할 수 있다면, 고객사에서 RAG 도입 여부를 빠르게 확인할 수 있을 것입니다.
생성형 답변 평가 방법은 크게 두 가지로 나눌 수 있습니다. 첫 번째는 BLEU, ROUGE, METEOR와 같은 N-gram matching 방법입니다. 이 방법은 생성 답변과 정답 간의 단어 일치도를 기반으로 평가합니다. BLEU Score의 경우, 단순히 단어의 일치도만을 평가하기 때문에 문장의 문법적 정확성이나 문맥적 일관성을 반영하지 못합니다. 예를 들어, "고양이가 매트 위에 있다" 대신 "매트가 고양이 위에 있다"라는 답변이 생성되었을 때, BLEU Score는 여전히 높게 나올 수 있지만 문장의 의미는 완전히 달라집니다.
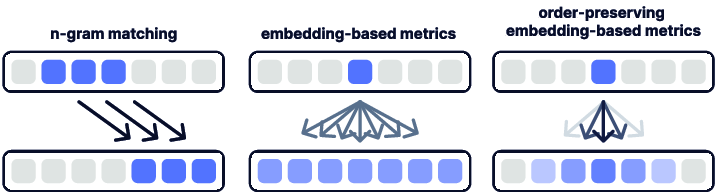
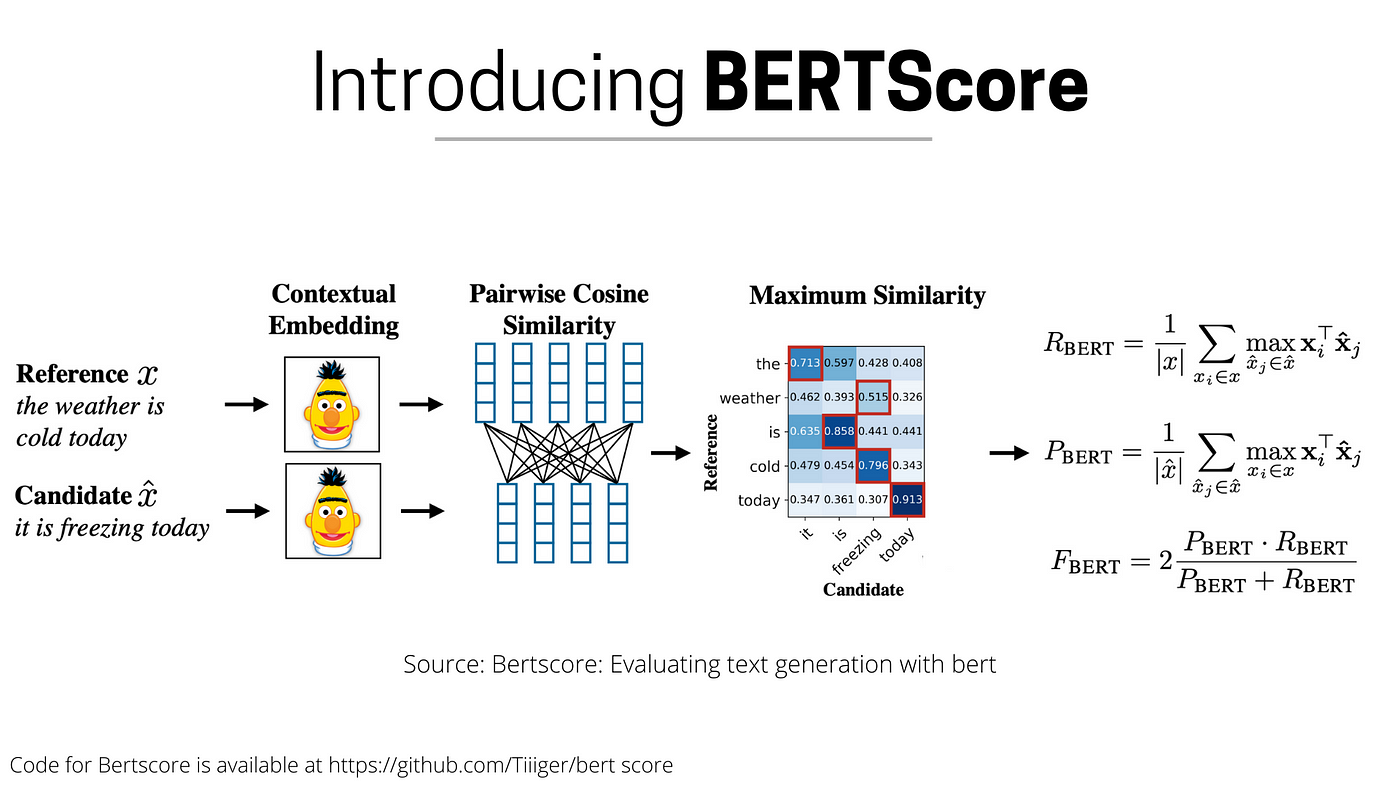
두 번째는 BERT Score 같이 생성 답변과 정답의 의미적 유사도를 비교하는 방법입니다. BERT Score는 BERT 모델을 사용해 문장을 임베딩 벡터로 변환합니다. 임베딩 벡터는 텍스트의 의미를 반영해 숫자로 변환한 결과입니다. 생성 답변의 벡터와 정답 벡터의 코사인 유사도를 계산합니다. BERT Score는 의미적 유사도를 파악하기 때문에, "고양이가 매트 위에 있다"와 "고양이가 깔개 위에 앉아 있다"가 관련있다는 것을 알 수 있습니다. 하지만, BERT Score는 BERT 모델 자체적인 한계가 있습니다. BERT는 최대 512 토큰 까지만 입력되며, 그 이상의 경우 문장이 잘립니다. 이런 경우 문장의 중요한 정보를 놓칠 수 있습니다. 또한, BERT는 특정 도메인의 데이터로 사전 훈련되었기 때문에, 훈련에 사용되지 않은 데이터에 대해 취약합니다.
이러한 한계 때문에, 최근에는 LLM Evaluation 방법이 대두되고 있습니다. LLM Evaluation은 생성된 답변의 문법적 정확성, 문맥적 일관성, 의미적 유사성을 종합적으로 평가합니다. 이를 통해 생성형 모델의 성능을 비교적 정확하게 평가할 수 있습니다.
2. LLM Eval 이란?
LLM Evaluation을 사용할 수 있는 대표적인 라이브러리로 RAGAS가 있습니다. RAGAS(Retrieval-Augmented Generation Assessment)는 RAG 파이프라인 평가툴을 제공하는, python 기반의 대표적인 오픈소스 라이브러리입니다.
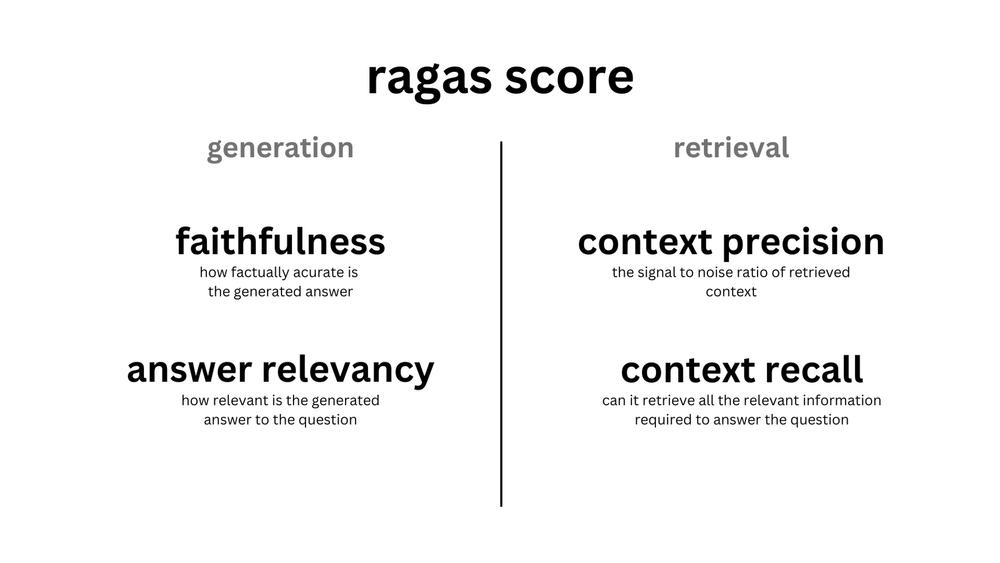
Faithfulness은 주어진 context에 대한 생성된 답변의 일관성을 측정합니다. faithfulness는 생성된 답변과 context를 비교하여 계산되며, (0, 1) 범위로 스케일링되는 높을수록 좋은 지표입니다.

Answer relavance는 생성된 답변이 주어진 프롬프트(질문)와 얼마나 관련성이 있는지를 평가합니다. 불완전하거나 중복된 정보를 포함하는 답변에는 낮은 점수가 부여됩니다.

Context precision는 context에 존재하는 ground-truth와 관련된 항목을 높은 순위로 잘 검색해 왔는지의 여부를 평가하는 Retrieval 관련 지표입니다. 질문과 context를 이용해 0에서 1 사이의 값으로 계산되며, 높을수록 좋은 지표입니다.

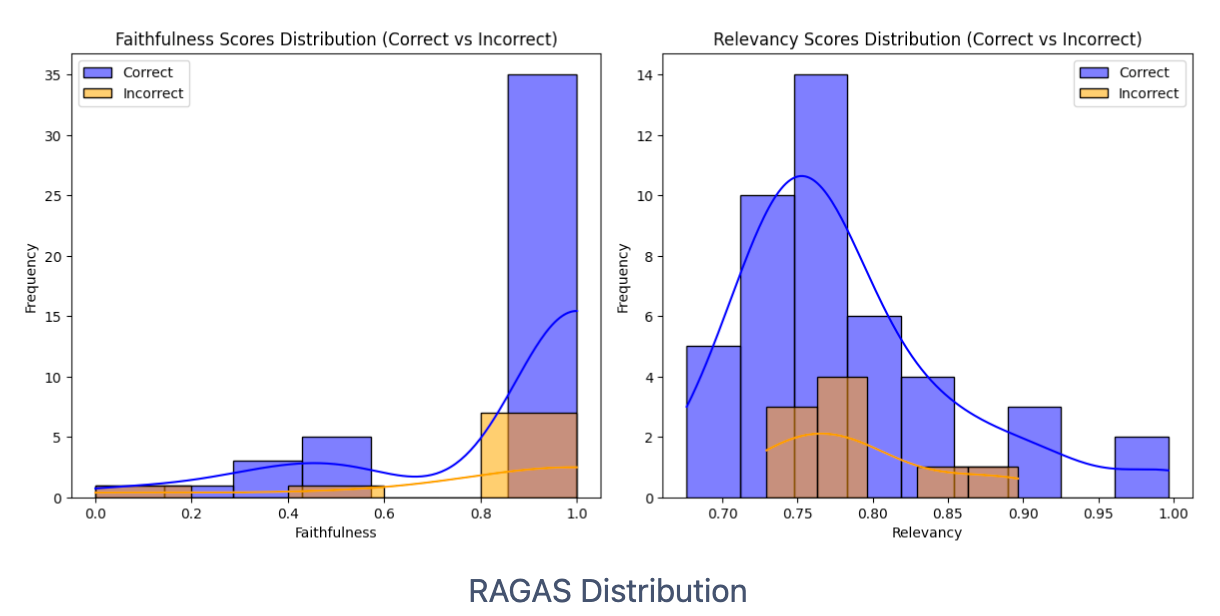
2024년 1월 올거나이즈 AI팀에서는 RAGAS를 이용해 자동 성능 평가 실험을 진행했습니다. 저희는 실제 데이터를 사용해 다양한 방법으로 실험을 진행했습니다. 실험의 성능 지표는 사람이 평가한 결과와 LLM Eval의 오차율을 기준으로 했습니다. 하지만, RAGAS만 사용했을 때, 오차율이 20% 정도 발생해, 실제 사용하기 어렵다고 결론 내렸습니다. 아래 표는 실제 데이터를 사용해 평가한 결과입니다.
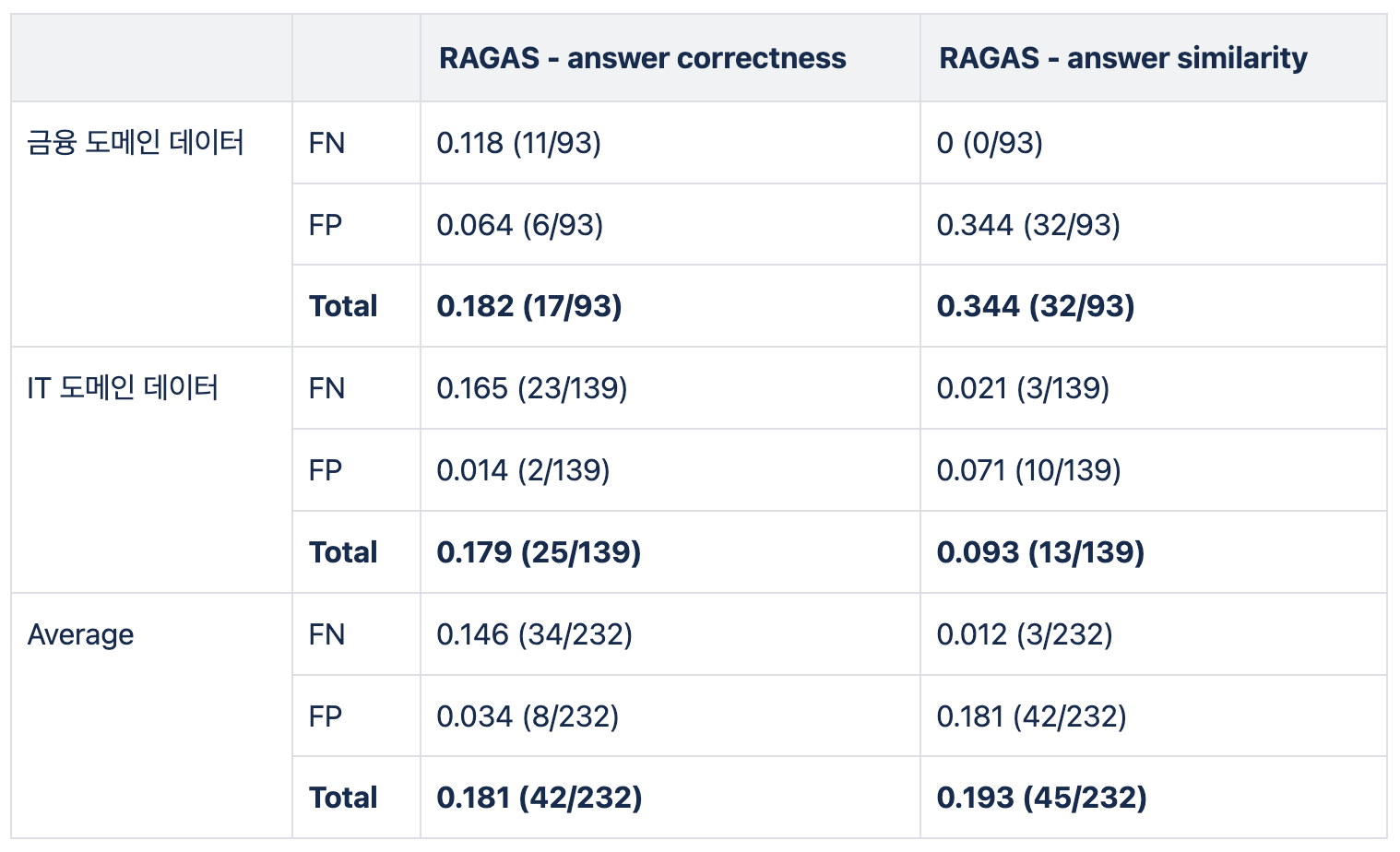
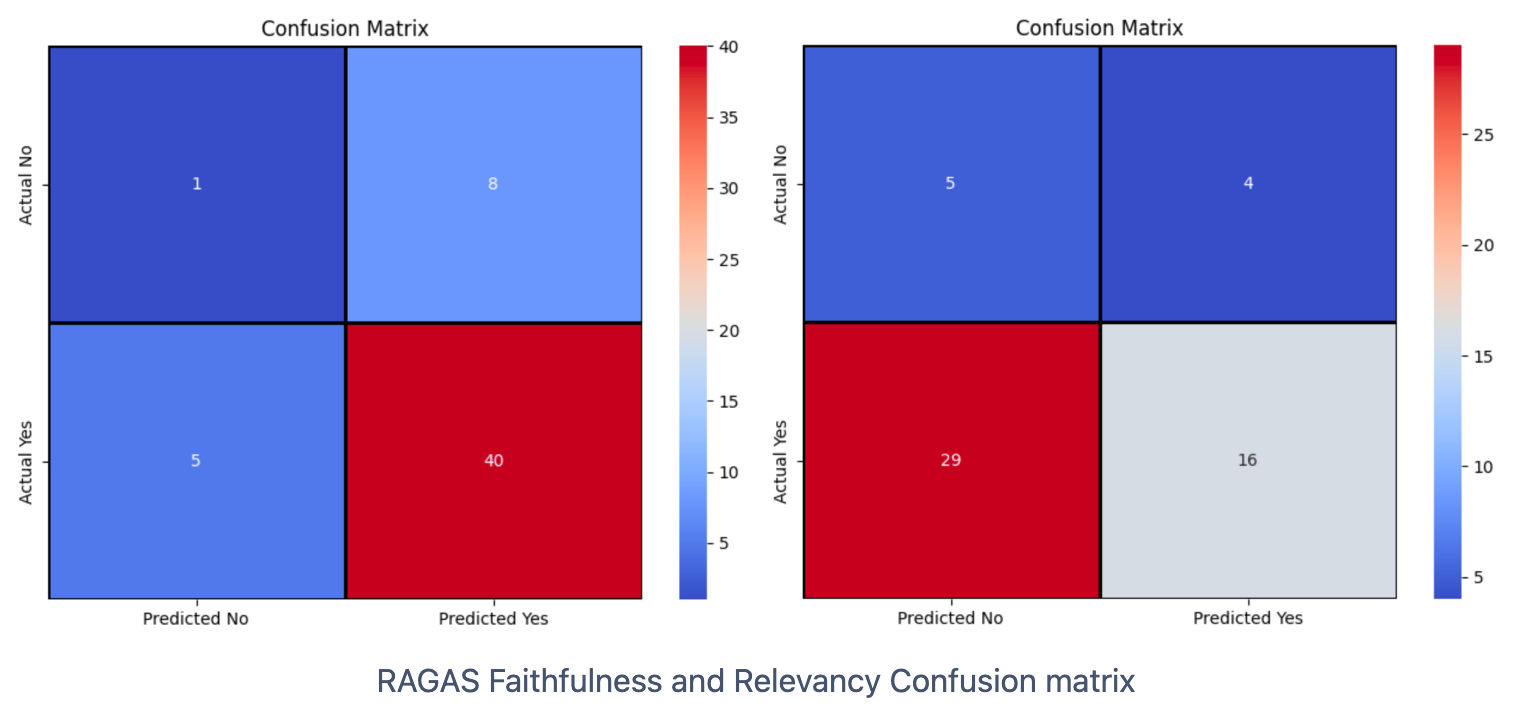
아래의 Confusion Matrix와 분포표는 올거나이즈 자체 데이터로 평가한 오차율입니다. 하단의 오른쪽 Confusion matrix를 보면, RAGAS-Relevancy의 Predict와 Actual이 모두 Yes인 경우는 54개 중 16개 밖에 되지 않습니다.
3. Ensemblem
RAGAS만을 사용한 실험의 오차율이 너무 높았기 때문에 새로운 방법으로 접근했습니다. RAGAS만 단독으로 사용하는 것이 아닌, 다른 평가 방법(TonicAI, GenAI, Claude기반의 올거나이즈 자체 평가 방법)을 함께 사용했습니다. TonicAI는 생성 답변과 정답의 유사도를 중심으로 평가합니다. GenAI는 유사도 뿐만 아니 정확성까지 함께 평가하도록 프롬프트를 구성했습니다. 하나의 데이터에 대해 여러가지 평가 방법을 개별적으로 적용한 후, 각 방법의 결과의 과반수를 정답으로 결정합니다. 평가 방법이 만약 점수가 생성된다면, threshold를 기준으로 O와 X로 분류합니다.

이렇게 Ensemble로 접근하니 20% 이상의 발생하던 오차율이 5%미만으로 감소했습니다. 오차율은 (오류갯수/ 전체갯수)이며, 낮을 수록 성능이 좋다는 것을 의미합니다.
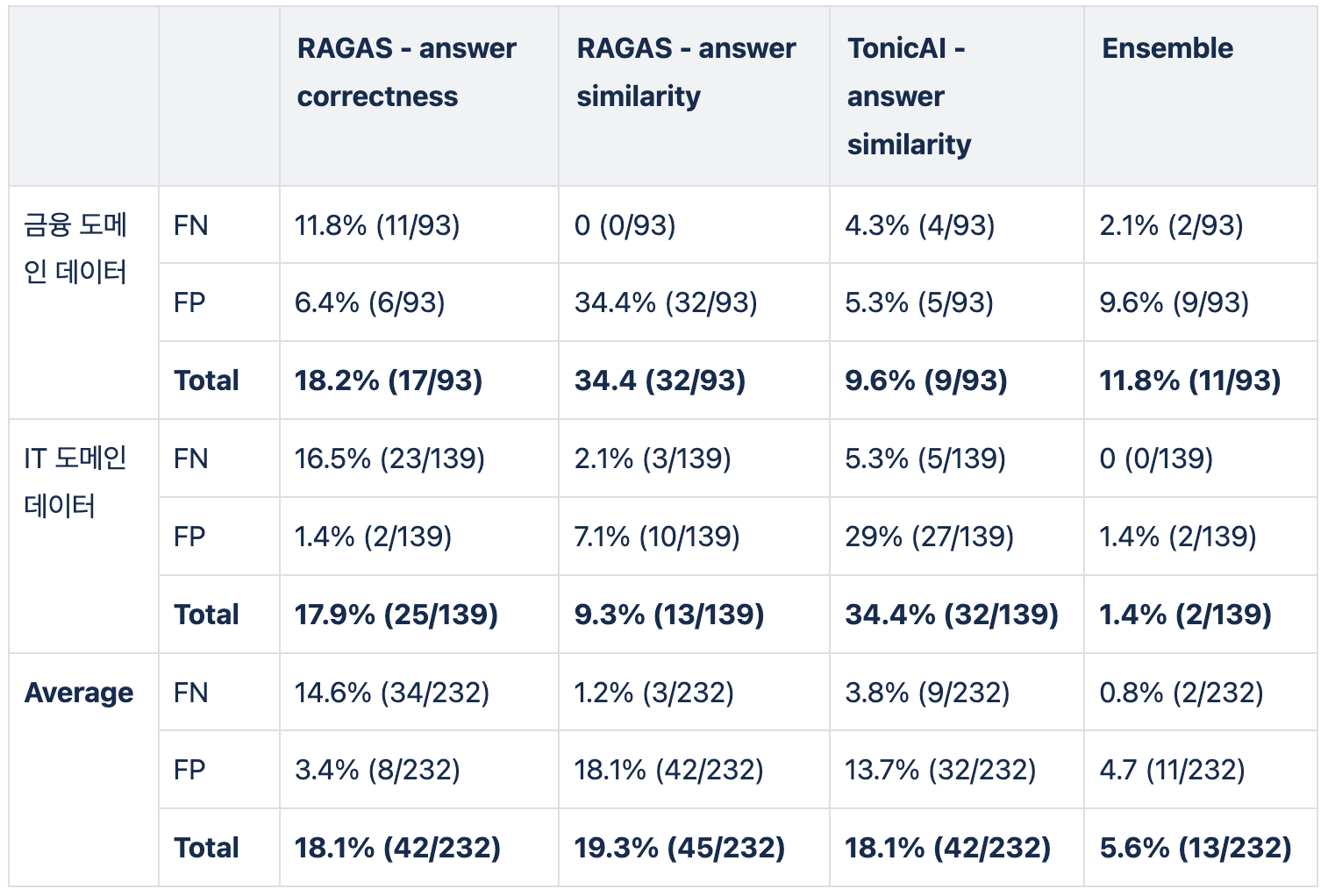
아래 표는 이전 실험에 TonicAI만 추가한 후, Ensemble한 평가 방법인데 18%의 오차율이 5%로 감소한 것을 확인할 수 있습니다. 해당 실험을 통해, Ensemble로 접근하는것이 오차율을 줄이는데 도움이 된다는 것을 알게 되었습니다.
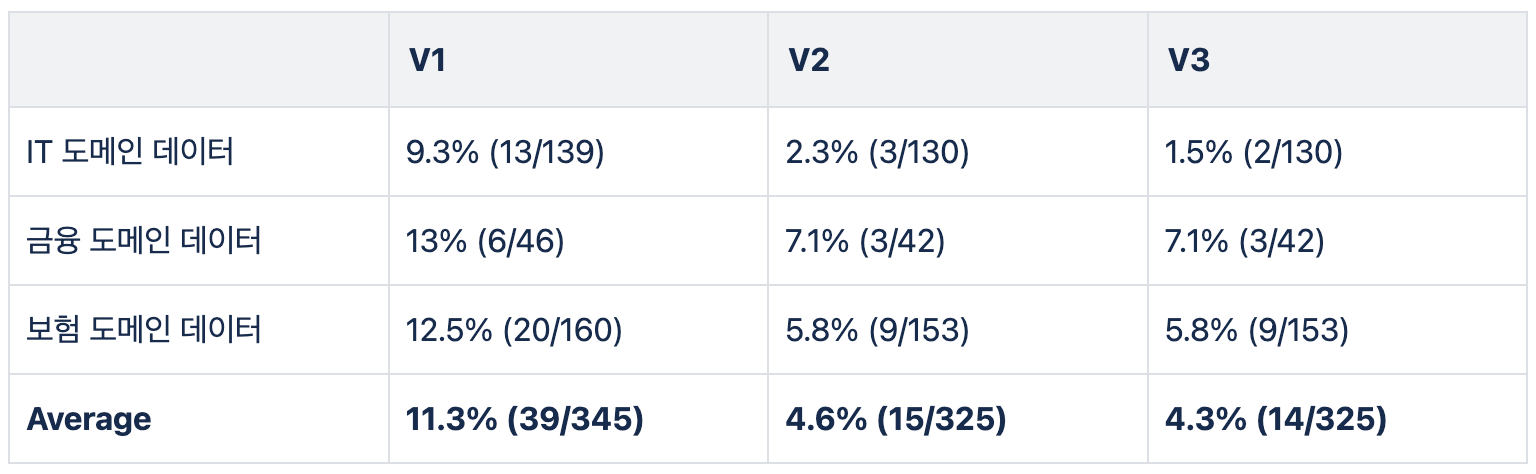
이후, GenAI 및 Allganize 평가 방법을 추가하여 다양한 실험을 진행했습니다. 특정 평가 방법을 제외하기도 하고 threshold를 변경하기도 하며 최적의 평가 방법을 찾았습니다. 좋은 성능의 기준은 앞서 실험과 동일하게 사람이 평가한 결과의 오차율입니다.
- V1
- RAGAS answer similarity :
threshold=0.6 - TonicAI answer similarity :
threshold=3 - GenAI answer similarity :
threshold=3 - GenAI answer correctness :
threshold=3 - Allganize answer correctness :
"O"or"X"
- RAGAS answer similarity :
- V2
- TonicAI answer similarity :
threshold=3 - GenAI answer correctness :
threshold=3
- TonicAI answer similarity :
- V3
- TonicAI answer similarity :
threshold=3 - GenAI answer similarity :
threshold=3 - GenAI answer correctness :
threshold=3 - Allganize answer correctness :
"O"or"X"
- TonicAI answer similarity :
아래 Colab에 접속하면, 자동 성능 평가 방법을 사용할 수 있도록 코드를 작성했습니다.

4. Future Work
하지만, 자동 성능 평가 방법에도 개선해야 될 점이 있습니다. 사람의 선호도를 반영하여 답변을 평가하지 못합니다. 자동 평가 방법은 정답에 있는 내용들이 생성 답변에 들어있는지를 체크하는 것이기 때문에, 선호도를 반영하지 못합니다. 예를 들어, 아래와 같이 너무 길게 생성된 답변은 사람이 선호하는 답변이 아닐 것 입니다. 하지만, 정답의 내용을 모두 포함하기 때문에, 자동 성능 평가 방법으로는 정답으로 판단할 것 입니다.

현재 자동 성능 평가의 오차율은 5% 내외입니다. 초기에 측정한 20%보다는 낮지만, 오차 범위로 생각하면 10%의 범위를 가지게 됩니다. 그래서 오차율을 1% 이하로 줄이기 위한 다양한 실험을 진행 중입니다.
LLM Eval 기반의 자동 성능 평가 방법을 통해, 100개 데이터 기준으로 2시간 동안 검증하던 작업이 10분 이내로 감소했습니다. 이로 인해, 더 많은 고객사의 데이터를 빠르게 정답을 판단할 수 있게 되었습니다. Alli의 Auto Evaluate를 통해 빠르고 간단하게 성능 평가를 진행해보는건 어떨까요?