생성형 AI 환각 해결 전략 - 하이라이트 구현
생성형 AI의 환각을 줄이기 위해 답의 근거가 되는 출처를 표기하는 서비스가 늘고 있습니다. 하지만 문서가 길고 복잡하면 출처 표기만으로는 근거를 제대로 찾기 어려운데요. 올거나이즈의 Alli는 근거를 하이라이트해서 표시해주고 있습니다. 하이라이트 기능이 필요한 이유와 구현 방법을 올거나이즈 이정훈 RAG 팀장이 설명해 드립니다.


챗GPT, 클로드, 제미나이 등 다양한 LLM 기반 서비스를 많이들 써보고 계실텐데요. 문서를 올리고 요약하거나, 문서에서 답을 찾거나, 문서 내용에 대해 질문을 던져보는 식으로 활용해보신 적 있나요?
최근에는 생성형 AI 모델의 환각을 줄이기 위해 답의 출처를 함께 표기해주는 서비스도 늘어나고 있습니다. 올거나이즈는 Alli에서 문서 출처를 표기해주는 것뿐만 아니라 답의 근거가 된 부분을 강조해서 표시해 주고 있는데요.
이런 하이라이트 기능이 필요한 이유와 하이라이트 기능 구현 방법에 대해 올거나이즈 이정훈 RAG 팀장이 자세히 설명해 드립니다.
1. Highlight가 필요한 이유
생성형 모델의 대표적 문제인 환각 현상(Hallucination)으로 인해, 고객들은 모델이 생성한 답변을 완전히 신뢰하지 못합니다. 일부는 모델 학습 과정을 새롭게 접근해 환각 문제를 해결하려 했지만, 아직까지 완벽한 방법을 못 찾고 있습니다. 그래서 여러 생성형 모델 제품들은 답변의 근거를 함께 제시하는 방법으로 신뢰성을 높이고 있습니다.
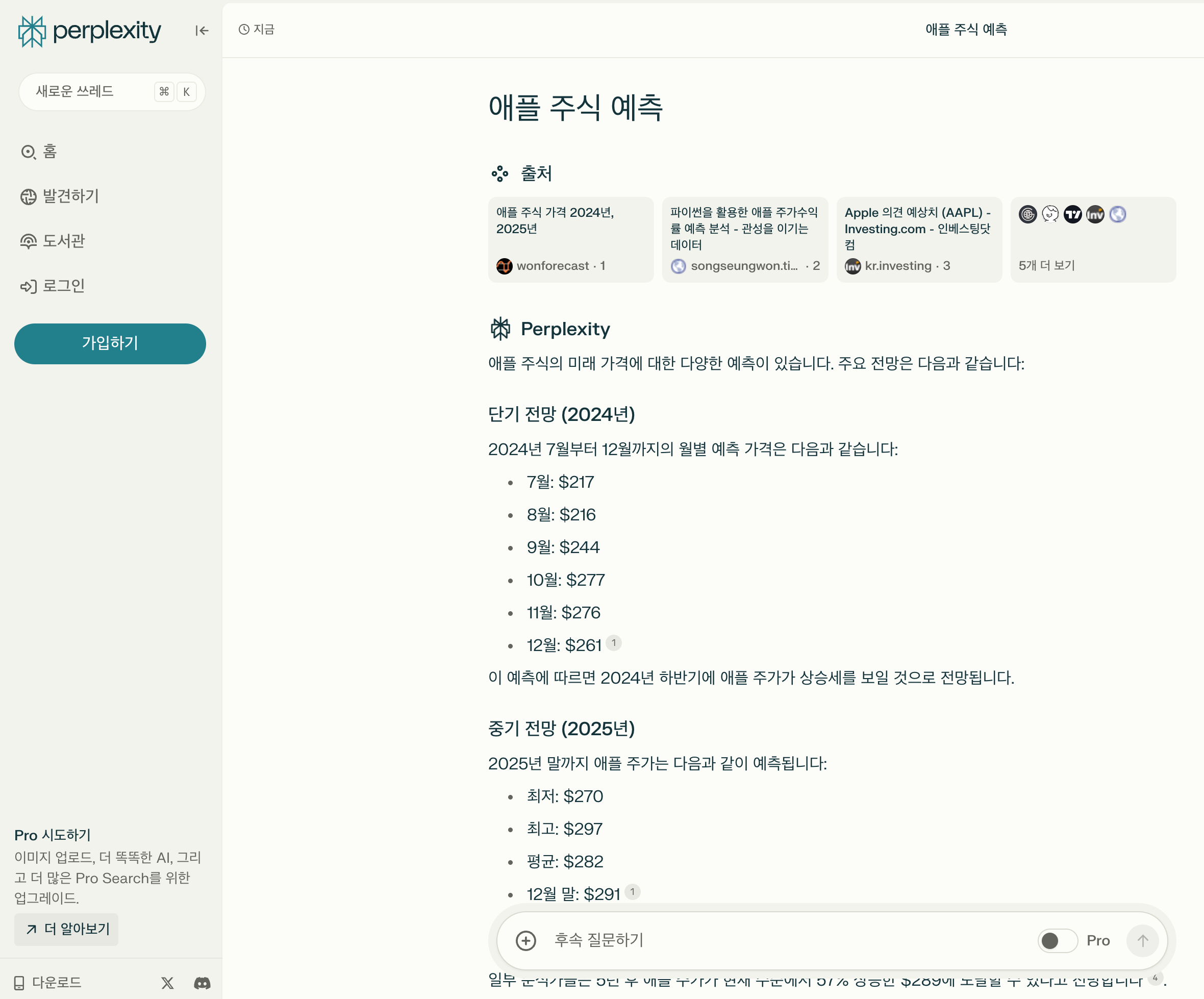
아래 이미지는 Perplexity의 답변 결과입니다. 답변의 출처를 함께 제공함으로써, 답변의 신뢰성을 더 높이고 있습니다.
Allganize의 Alli 또한 답변의 출처를 미리보기 형식으로 제공하고 있습니다. 아래 이미지를 보면, [1], [2], [3]으로 답변의 근거가 되는 문서의 페이지를 표시하고 있습니다. [2]를 클릭하면 해당 답변의 근거가 되는 페이지를 미리보기로 보여줍니다.

그러나 한 페이지에 텍스트가 많을 경우, 고객이 이를 읽고 이해하는 데 시간이 많이 소요됩니다. 특히, 금융 및 법률 같은 생소하고 어려운 도메인의 경우에는 더욱 많은 시간이 소요됩니다. 예를 들어, 금융 도메인에 익숙하지 않은 고객이 아래와 같은 페이지를 빠르게 읽고 내용을 이해하는 것은 매우 어려운 일입니다.

2. Highlight란?
이러한 문제를 해결하기 위해, 전체 페이지에서 답변의 근거가 되는 부분을 강조하여 보여준다면 훨씬 빠르게 문서를 확인할 수 있을 것입니다. Allganize의 Alli는 답변의 근거 부분을 노란색 배경색으로 프리뷰 화면에 표시합니다. Allganize의 하이라이트 모델은 한국어, 영어, 일본어 등 다양한 언어에 대응할 수 있습니다. 한국어 테스트 데이터로 성능을 평가한 결과, 82%의 정확도를 보였습니다.
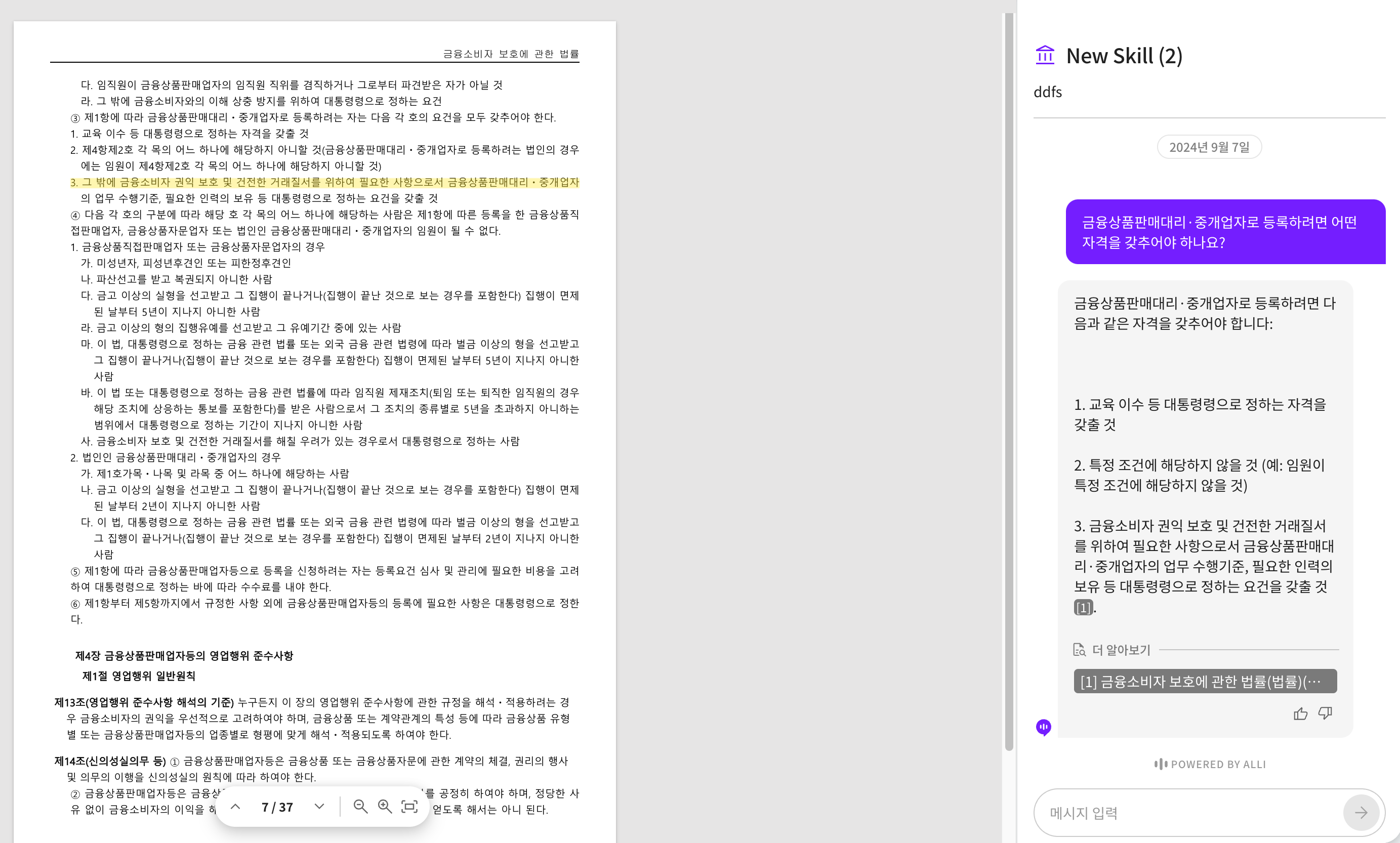
Alli에 금융상품판매대리·중개업자로 등록하려면 어떤 자격을 갖추어야 하나요? 라는 질문을 했고 아래와 같은 답변을 생성했습니다.

아래 이미지를 보면, 답변의 근거가 되는 부분이 하이라이트 된 것을 확인할 수 있습니다.
3. 구현 방법
3-1. Data
하이라이트 구현에 사용한 데이터의 형태는 아래와 같습니다.
입력 텍스트는 Context, Query, Answer가 하나의 세트로 구성됩니다.

라벨(Label)은 0과 1로 구성됩니다. 답변이 해당 문단에서 도출될 수 있으면 1, 그렇지 않으면 0으로 표시됩니다. 데이터는 AI-Hub의 오픈된 MRC 데이터와 자체 제작한 데이터를 합쳐서 사용했습니다.

3-2. Query and Document Embedding
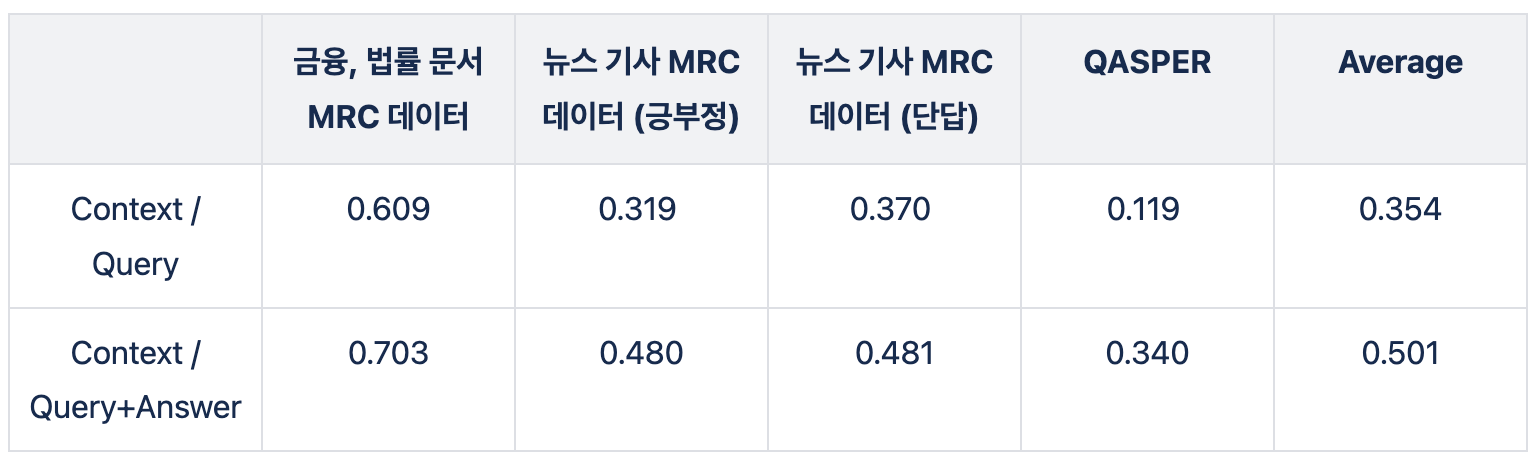
첫번째 방법으로 간단하게 Query와 Context를 Universal Sentence Embedding(USE)로 임베딩 했습니다. 그리고 유사도 점수가 높은 Context를 답변의 근거로 선택했습니다. Context는 한 페이지에 있는 텍스트를 특정 길이로 나눈 토큰들입니다. 해당 방법은 장점은 Bi Encoder 방식이기 때문에, latency가 짧습니다. Bi Encoder 방식은 Context를 사전에 임베딩으로 변환 후, DB에 저장합니다. 그래서 Query가 입력할 때마다, Query만 임베딩으로 변환하면 됩니다.
두번째 방법으로, Query만 사용하는 것이 아닌 Query + Answer를 함께 사용해서 임베딩을 만들고 Context와 비교하는 방법입니다. Query의 정보가 제한적이기 때문에, Answer의 정보를 추가하면 근거를 찾을 가능성이 높아진다고 생각했습니다.
실험을 진행했고, Answer를 추가한 방법의 성능이 더 높은 것을 확인했습니다. 실험은 4종류의 테스트 데이터를 사용했고, F1 Score 입니다.
3-3. Embedding
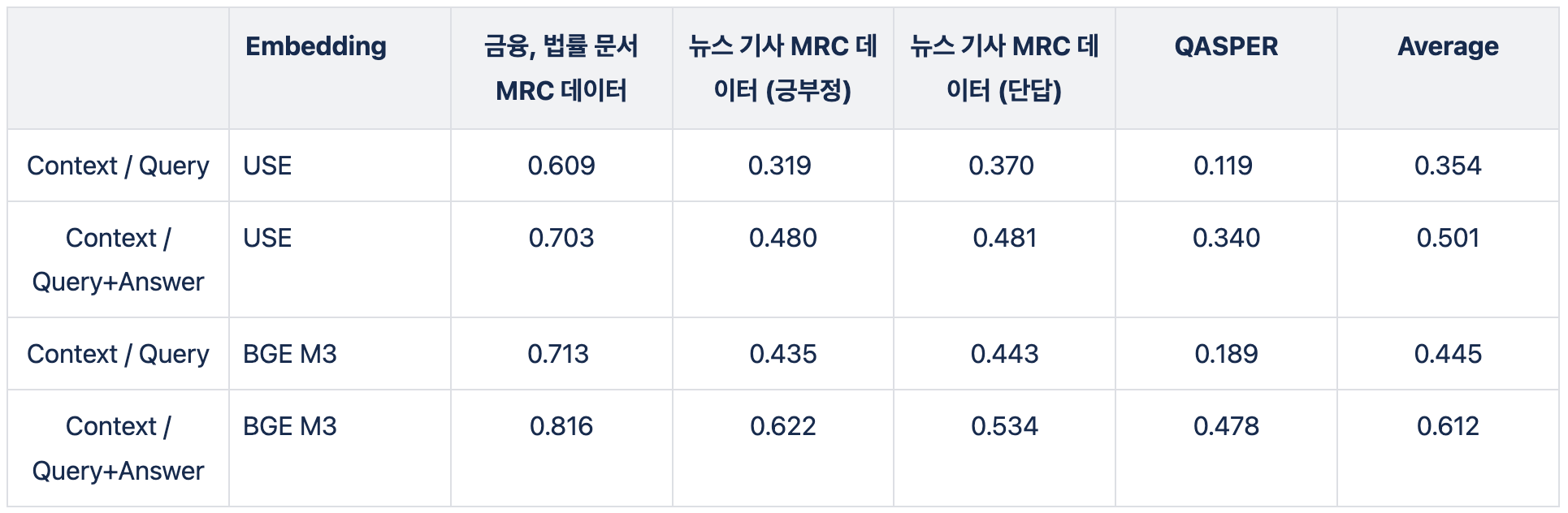
위의 실험을 기반으로 다른 임베딩 모델을 사용해서 성능을 비교했습니다. USE는 속도가 빠르고 토큰의 제한이 없다는 장점이 있지만, 임베딩 성능이 좋지 못합니다. 그래서, 성능 좋은 임베딩인 BGE M3를 사용해 성능이 얼마나 개선되는지 확인했습니다. BGE M3는 최대 입력 토큰 개수는 8K이기 때문에 Context 길이의 부담이 줄어듭니다. 또한, BGE M3는 Allganize 내부 Retrieval Leaderboard에서 가장 좋은 성능을 보여준 모델입니다. (가장 좋은 모델은, BAAI/bge-multilingual-gemma2 이였지만, sLLM 모델이라 현실적으로 사용하기 어렵습니다.)
결과는 아래 표에서 확인할 수 있듯이, BGE-M3 모델을 사용하니 더 높은 성능이 나왔습니다.
3-4. Overlap
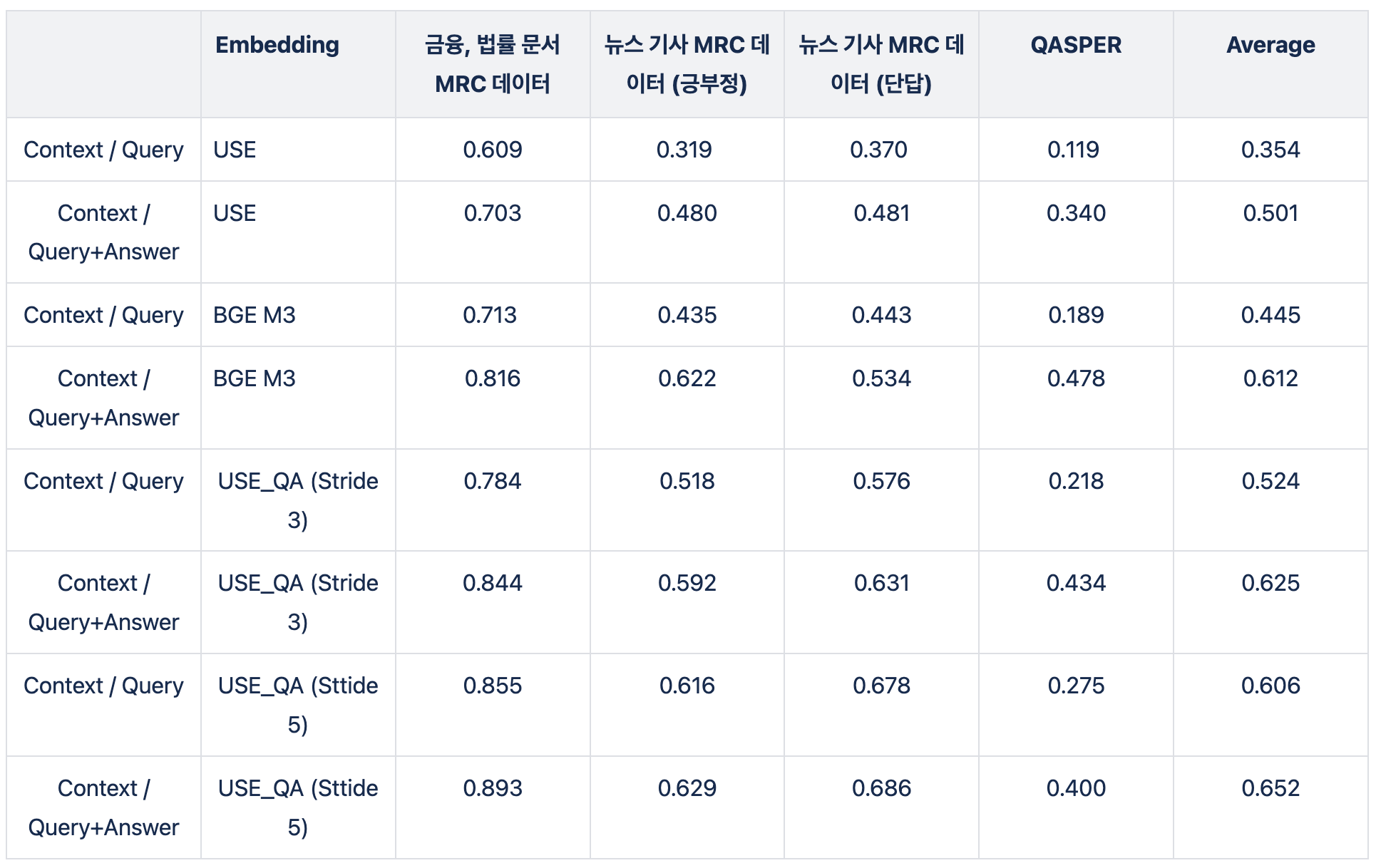
위에서 했던 실험은, Context를 특정 길이에 맞춰 나누는 방법입니다. 이렇게 되면, Context에 유실되는 정보가 많을 것이기 때문에 Overlap해서 성능을 평가했습니다.
USE로 평가했을 때, Overlap 했을 때보다 성능이 더 좋아진 것을 확인했습니다.
3-5. BERT
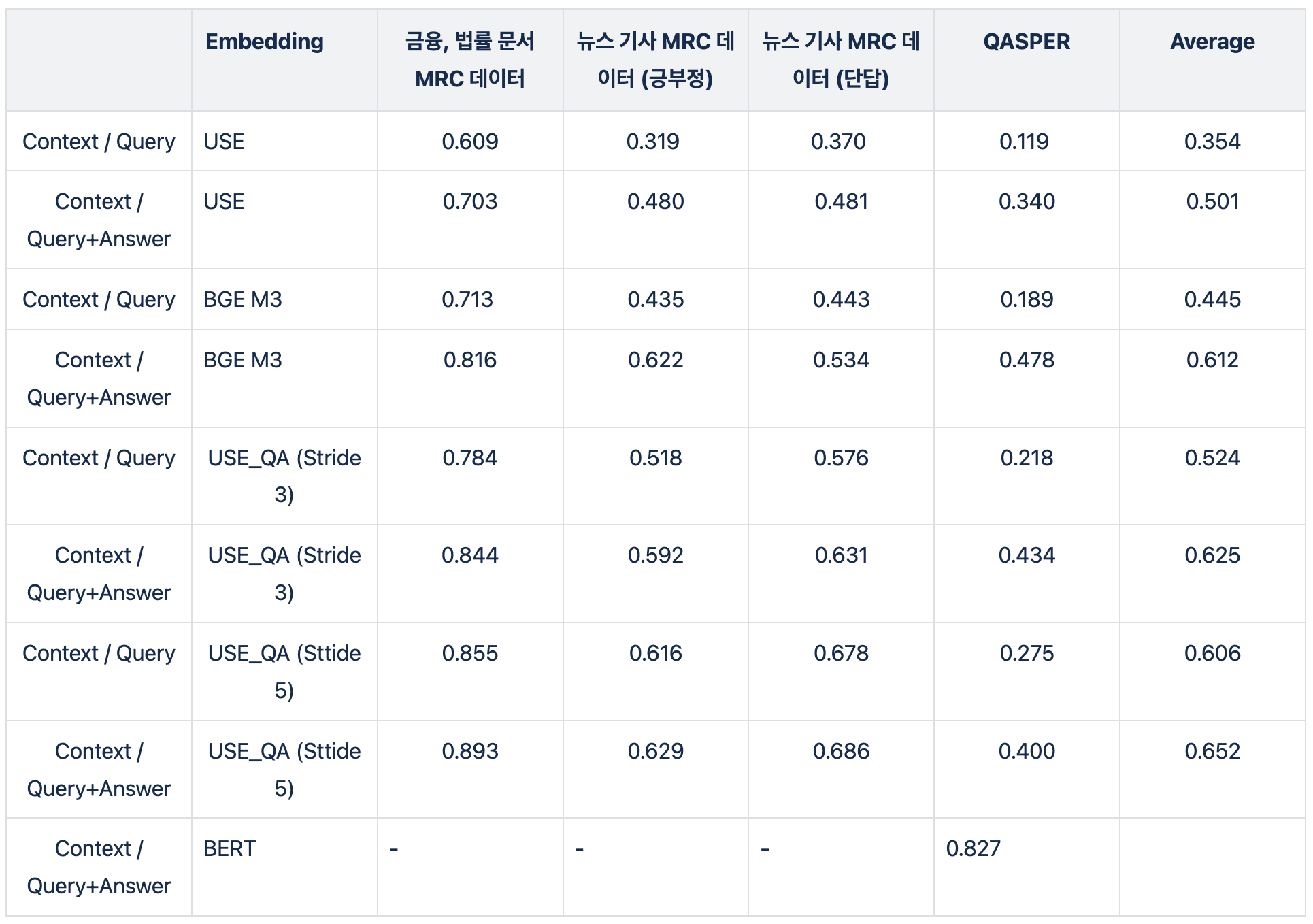
위와 실험 같이, Bi Encoder 방법으로 접근했지만 성능이 아쉬웠습니다. 그래서 latency를 일부 포기하고 Cross Encoder 방법으로 새롭게 접근했습니다. Cross Encoder는 Context와 Query를 모델에 함께 입력하기 때문에, 매번 질문이 입력 될 때마다, 전체 Context와 Inference가 모두 진행됩니다.
이렇게 되면 시간이 너무 오래걸리니, 전체 Context가 아닌 retriever를 거친 page를 대상으로 제한했습니다. latency에 대한 부담이 줄었지만, 그래도 오래 걸리면 부담스럽기 때문에 상대적으로 가벼운 BERT로 실험을 진행했습니다. BERT의 최대 토큰이 512 토큰이라 짧아서 부담이 있지만, Context와 Answer는 상대적으로 짧기때문에 대부분은 512 토큰내에 들어올 수 있었습니다.
BERT부터는 성능 평가 데이터가 달라져, 기존의 성능 평가봐 비교한 할 수 있는 데이터가 QASPER 데이터 뿐입니다. 다른 방법들보다 월등히 성능이 좋아진 것을 확인할 수 있습니다.
3-6. Multilingual
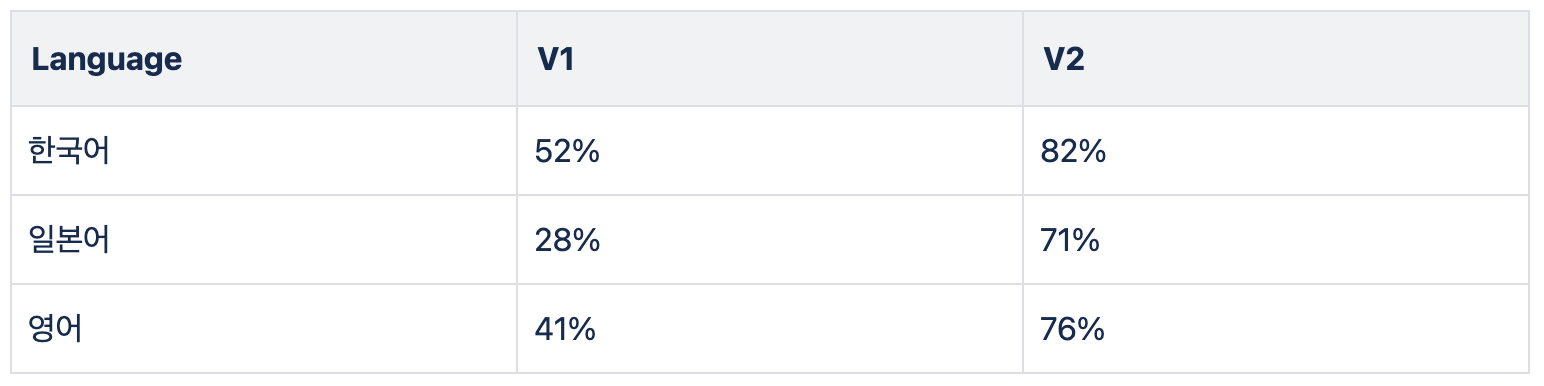
Allganize는 한국 뿐만 아니라 일본과 미국에도 세일즈를 하고 있습니다. 그렇기 때문에, 일본어와 영어에도 대응되는 하이라이트 모델을 만들어야 했습니다. 실제 고객사 데이터를 사용해 평가해보니, 아래와 같이 낮은 성능이 나왔습니다. 그래서, 데이터를 추가로 생성하고 일본어와 영어로 변역하여, 학습을 시키니 아래와 같이 성능이 향상되었습니다.
4. Future Work
Allganize에서는 하이라이트 모델의 성능을 90% 이상 향상 시키려 합니다. BERT 모델이 아닌, sLLM 모델을 사용하는 실험도 진행해보고, OpenAI GPT 4o 모델을 사용해 평가하는 실험도 진행 중입니다.
Allganize는 고객의 편의성을 극대화하기 위해, UI/UX와 프로덕트 면에서 항상 신중하게 접근하고 있습니다. RAG 솔루션의 핵심은 좋은 답변을 제공하는 것이지만, 성능이 항상 100%일 수 없기 때문에 서비스 측면에서 이러한 단점을 보완하는 방법을 적용했습니다.
사용성 좋은 RAG 솔루션을 제대로 적용하고 싶다면, 올거나이즈가 도와드리겠습니다. RAG 솔루션에 대한 시연과 데모가 필요하시면 아래에 문의를 남겨주세요.
