'Alpha V2' 모델 공개 : 일반 작업에 특화된 한국어 LLM


Allganize의 LLM팀은 지속적인 연구와 개발을 통해 '한국어 특화 인공지능 언어 모델, Alpha V2 Small과 Medium'을 발표하게 되었습니다. 이 모델들은 한국어에 최적화된 뛰어난 성능을 자랑하며, 일상적인 업무부터 복잡한 전문적 작업까지 다양한 분야에서 탁월한 효과를 제공합니다.
Alpha V2 모델은 한국어 처리 성능에 특히 강점을 두고 개발된 모델로서, 기존에 글로벌 최상위 성능을 자랑했던 오픈 웨이트(Open-weight) 모델을 능가하는 성과를 달성했습니다. 이는 단순히 국내 사용자만을 위한 솔루션이 아니라, 영어 기반 글로벌 환경에서도 탁월한 성능을 보이며 국제적 경쟁력을 갖춘 AI 모델로 자리 잡고 있습니다.
Alpha V2의 모델 성능
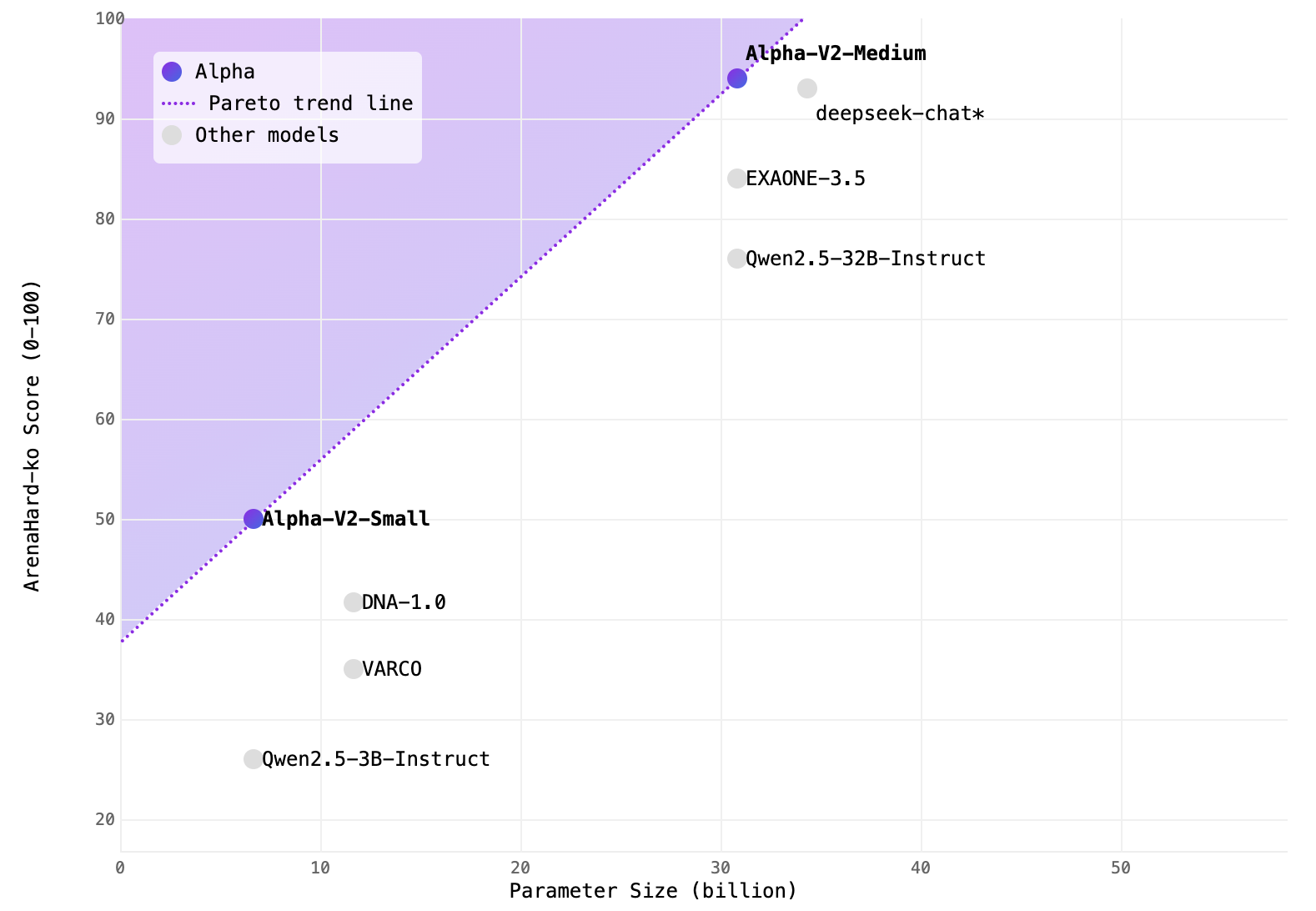
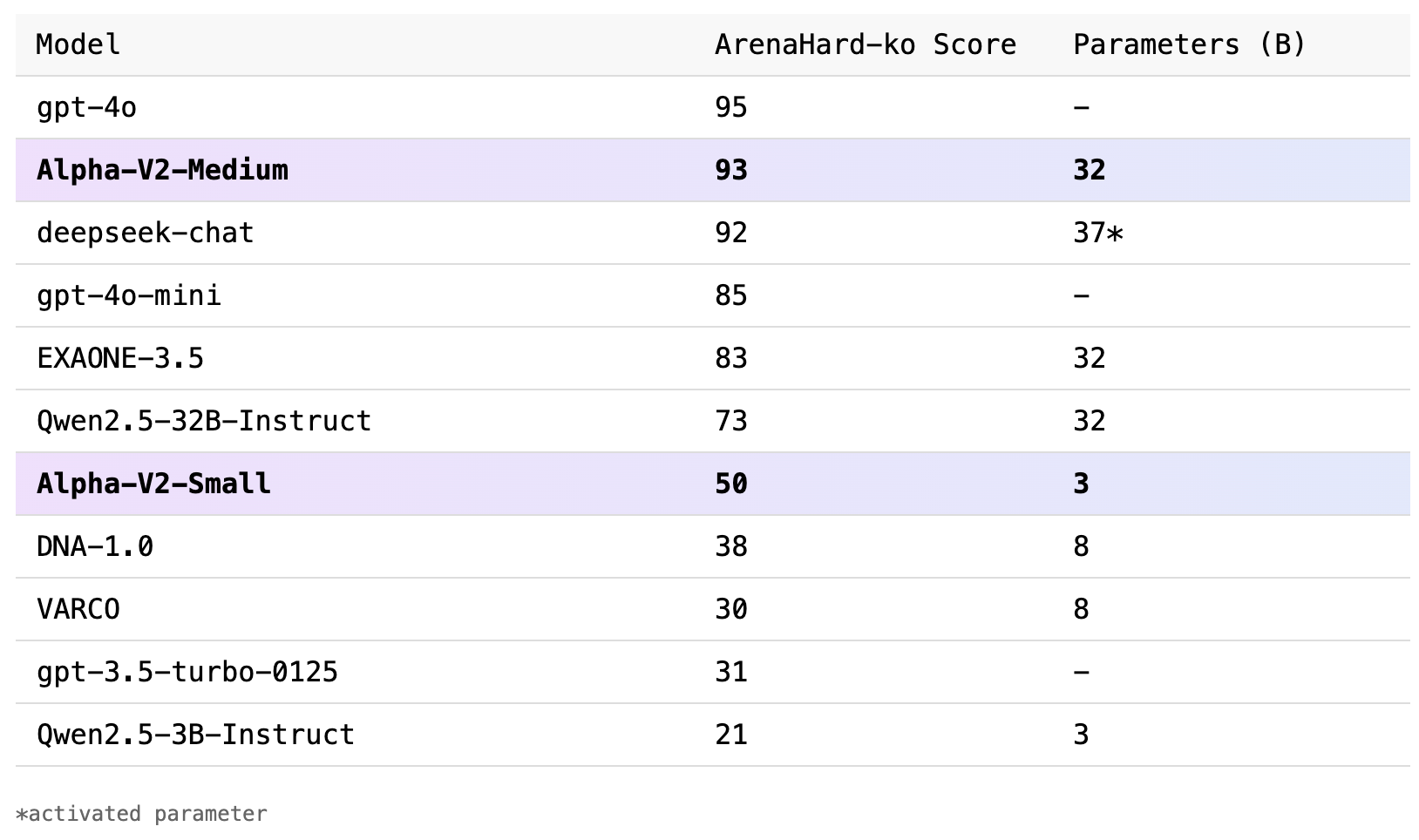
Alpha-V2-Small : 8B 보다 뛰어난 3B Model
Alpha V2 Small 모델은 30억 개의 파라미터를 가지고 있으며, HuggingFace 플랫폼을 통해 누구나 쉽게 접근 가능한 오픈 웨이트 모델로 제공됩니다. 이 모델은 Qwen2.5-3B, gemma-2-2b-it, ibm-granite-3.2-2b와 같은 기존 동급 모델들과의 비교에서 69%에서 79%의 높은 승률을 기록하였습니다. 특히 더 큰 모델인 Llama-DNA-1.0-8B-Instruct, Llama-VARCO-8B-Instruct 모델보다도 뛰어난 성능을 보여, 제한된 하드웨어 자원에서도 효율적인 운영이 가능한 모델입니다.
이 모델은 신속함이 요구되는 매우 다양한 분야에서 활용할 수 있습니다. 예를 들어, 고객 지원 업무에서는 자동화된 상담 시스템을 통해 고객의 요구에 신속한 응답이 가능해져 서비스 품질 향상과 운영 비용 절감을 동시에 실현할 수 있습니다. 또한 금융권에서는 계약서 분석, 투자 보고서 작성, 금융 리스크 평가와 같은 업무를 자동화하여 업무 효율성을 극대화할 수 있습니다. 또한 법무 부서나 연구 기관에서는 방대한 문서 자료에서 필요한 정보를 빠르게 추출하고, 신속하게 요약하여 업무 생산성을 획기적으로 높일 수 있습니다. 이를 통해 기존에는 수일이 걸리던 문헌 분석 작업이 단 몇 시간으로 단축될 수 있으며, 인적 자원의 부담을 크게 경감시키는 효과를 누릴 수 있습니다.
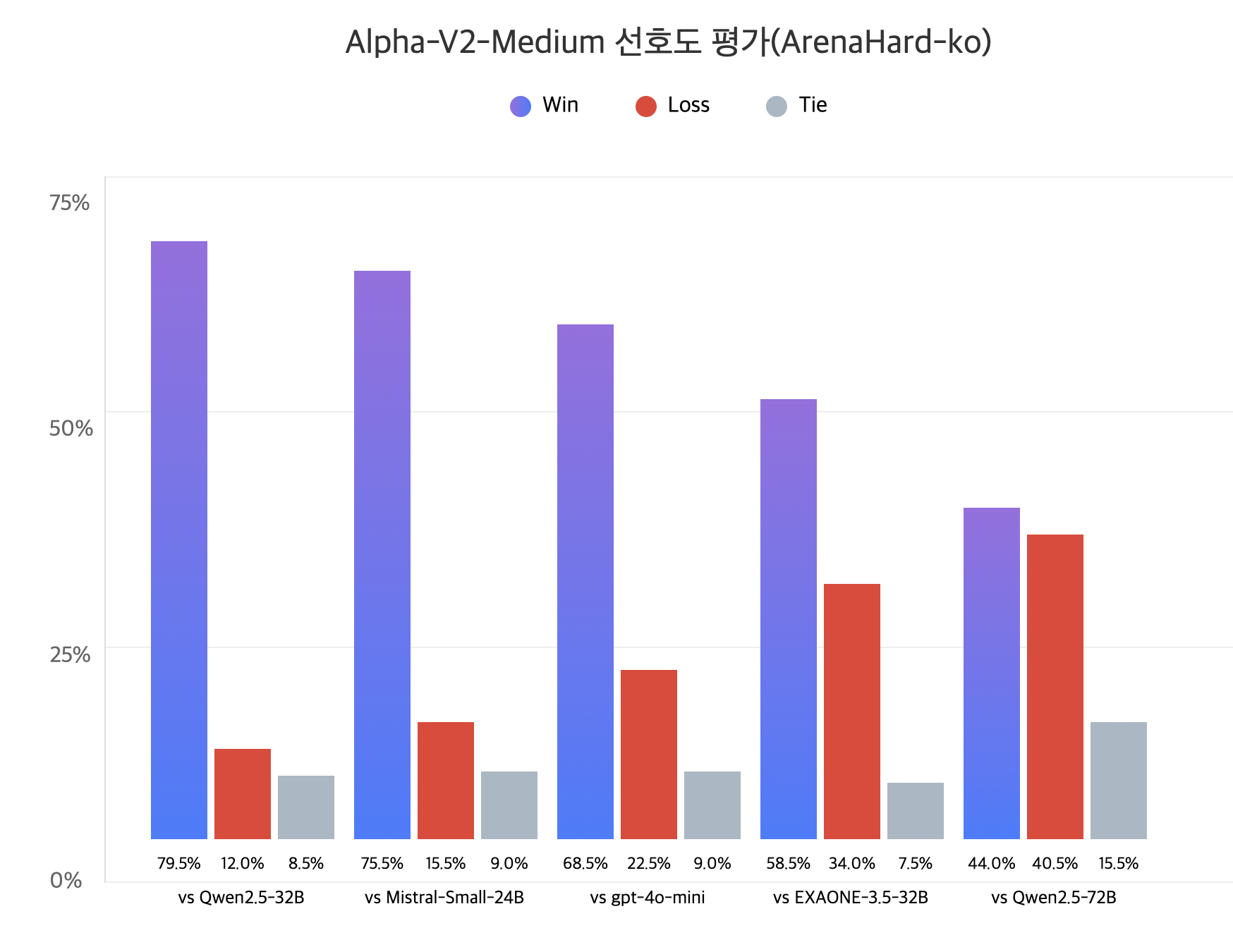
Alpha-V2-Medium : 72B를 압도하는 32B Model
Allganize 파이프라인을 통해 독점 제공되는 Alpha V2 Medium 모델은 320억 개의 파라미터로 더욱 강력한 성능을 제공합니다. 특히 Qwen2.5-32B, EXAONE 3.5-32B 모델을 포함하여 파라미터 수가 2배 이상 많은 Qwen2.5-72B 모델까지 압도하는 성능을 발휘하며, 한국어 언어 모델의 새로운 벤치마크로 자리 잡았습니다.
이 모델은 높은 정확성과 신속한 처리 속도를 모두 요구하는 업무 분야에서 특히 빛을 발합니다. 예를 들면,
- 보험 산업에서는 복잡한 보험 약관 분석, 고객 맞춤형 보험 상품 추천, 보험 사기 예방 시스템 구축에 효과적으로 활용될 수 있습니다.
- 공공기관 및 행정 부서에서는 민원 상담 자동화 시스템을 통해 업무 효율성을 높이고 민원인의 만족도를 크게 향상시킬 수 있습니다.
- 교육 분야에서도 Alpha 모델을 활용하여 개인 맞춤형 학습 콘텐츠 제작, AI 기반 학습 평가 및 관리 시스템 구축 등을 통해 학생 개개인의 학습 효율성과 성취도를 높이는 데 기여할 수 있습니다.
모델 개발 및 학습 과정
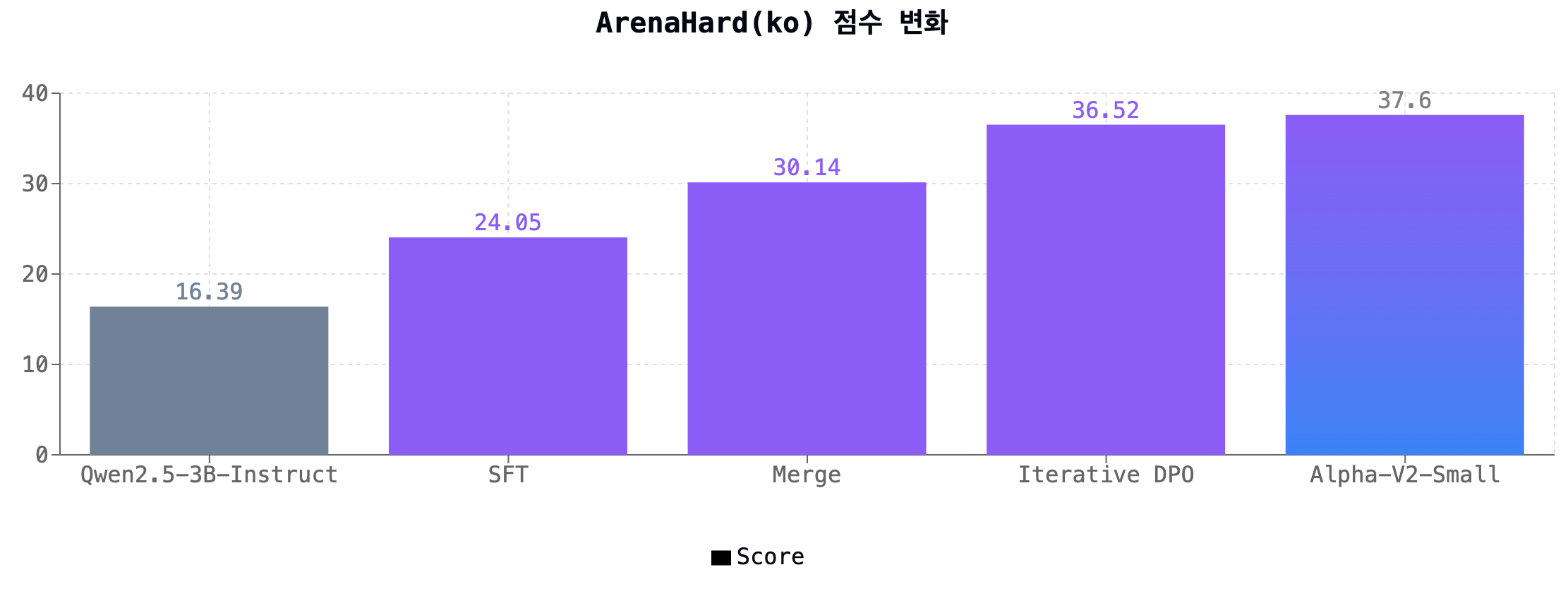
Alpha-V2 모델의 뛰어난 성능 개선은 크게 합성 데이터 파이프라인 및 전처리, 모델 병합(Model Merging), 그리고 Iterative DPO를 통한 정렬이라는 세 가지 핵심적인 요소로 이루어졌습니다.
- 합성 데이터 파이프라인 및 전처리
- Evol-instruct 방법론을 활용하여 소규모의 시드 데이터로부터도 충분한 크기의 지시(instruction) 데이터셋을 생성할 수 있는 합성 데이터 파이프라인을 구축했습니다.
- 올거나이즈는 또한 검증자 및 한국어 문법 검사를 포함한 여러 실전적인 노하우를 적용하여 고품질의 한국어 데이터셋을 구축하였습니다.
특히 Alpha V2 Small 모델 개발 과정에서는 Evolkit 기반의 evolkit-20k 데이터와 추가적인 한국어 데이터셋만을 사용하여, 제한된 데이터 조건에서도 이미 Qwen 모델 성능을 뛰어넘는 성과를 달성하였습니다.
- 모델 병합(Model Merging)
- Supervised fine-tuning 이후 모델 병합을 진행하여, 병합된 모델이 이전 모델 대비 지식 전달, 지시 수행, 추론, STEM 평가 및 인간의 선호도 측면 등 모든 평가 지표에서 눈에 띄는 성능 향상을 나타냈습니다.
- 또한 Alignment 학습 이후 추가적인 모델 병합 단계를 통해 Alignment 학습 과정에서 나타나는 망각 현상을 줄이는 효과도 얻었습니다.
- 정렬 - Iterative DPO
- 기존의 DPO 방식을 한 단계 발전시킨 Iterative DPO를 도입하여 on-policy 강화학습(RL)에 준하는 높은 성능을 얻을 수 있었습니다.
- Prompt 시드 데이터만을 활용한 Iterative DPO 방식은 Teacher 모델 없이도 학습이 가능하여 추가적인 데이터셋 준비의 부담을 크게 경감시켰습니다. 더불어 기존의 reward 모델을 활용했을 때도 한국어 모델에서 충분한 성능이 나타나 별도의 reward 모델 개발에 따른 추가 리소스 투입도 줄일 수 있었습니다.
향후 목표 : Agent에 특화된 온프레미스 LLM 개발
Alpha 모델은 단순히 On-premise 환경에서 생성형 답변 제공을 위한 로컬 모델의 역할을 넘어서 Allganize의 기존 파이프라인 및 에이전트 시스템과 유기적으로 결합하여 고객에게 차별화된 새로운 경험을 제공하기 위한 첫 번째 마일스톤입니다.
앞으로 Allganize는 하나의 모델에서 기존 답변과 추론 답변을 자유롭게 전환하여 제공할 수 있는 Deep Thinking 모델 개발, rule 기반 검증을 통해 Agent 목표를 설정하고 보상 학습을 수행하는 Alpha Agent 개발, 멀티모달 학습 파이프라인 구축 등 다양한 후속 프로젝트를 준비하고 있습니다.
곧 두 번째 마일스톤에 대한 새로운 업데이트가 있을 예정이오니 많은 관심과 기대 부탁 드립니다.