기업용 금융 특화 LLM 모델 만들기 (2)- 학습전략과 비용
회사 내부의 약어, 전문 용어를 알아듣는 AI를 도입하려면, 비용이 어떻게 될까요? 데이터는 얼마나 준비해야 할까요? ROI를 위한 성능 평가는 어떻게 해야할까요? 기업용 금융 특화 LLM 모델을 만든 올거나이즈의 신기빈 CAIO가 LLM 학습 전략과 노하우를 상세하게 공유합니다.

올거나이즈(Allganize)는 금융 산업에 특화된 한국어 LLM모델(알리 파이낸스 LLM)을 출시했습니다. 금융 특화 한국어 LLM모델을 만들기까지 올거나이즈팀이 해왔던 고민과 학습 전략, 성능 평가, 비용 등에 대한 이야기를 신기빈 CAIO(Chief AI Officer)가 두 차례에 걸쳐 공유해 드립니다.
1편은 아래에서 보실 수 있습니다.
 Allganize Korea
Allganize Korea
이번 편은 오픈 소스 LLM을 바탕으로 sLLM을 만들면서 경량화 방법을 고민하는 분들, 산업 특화 sLLM을 만들 때 우리 기업의 데이터는 얼마나 확보해야 효과를 볼 수 있을지 학습 전략과 비용을 고민하는 분들이 보시면 좋습니다.
학습 전략
자 이제 기업용 on-prem model을 만드려고 합니다. 어떤 foundation model을 사용해야할까요? 그리고 얼마나 많은 데이터를 학습시켜야할까요?
그전에 우리는 이 llm을 서비스하고 학습시키는데 얼마정도의 비용을 들여야할까요?
우리가 만나고 이야기했던 고객들의 상황을 통해서 몇가지 가정을 하였습니다.
- 고객이 풀고자하는 가장 큰 문제는 답변 찾기이다. 따라서 답변 찾기(RAG)를 잘 할 수 있는 모델이어야한다.
- 고객이 가지고 있는 자료의 양은 많지 않다. 정확히 말하면 학습을 하기 위해 정제된 데이터는 많지 않다.
- 초기부터 모델의 학습및 서비스 비용을 들이고 싶어하지 않는다.
사실 2번으로 부터 모두 연결된 문제입니다. 데이터가 많지 않으니 큰 모델을 학습시킬수 없고 작은 모델은 학습과 서비스 비용이 크지 않으니까요.
그렇다면 어느 정도 데이터가 큰 걸까요?
BloombergGPT는 모두 700B token을 학습하였습니다. 50B모델이구요. llama2가 2T token을 학습했다고 하니 학습 규모로만 보면 1/3정도 되네요.
pdf 보고서 하나를 예로 들어보죠. 한국은행에서 발행한 8월 경제전망보고서는 총 68page입니다. text만 모두 읽으면 68417자네요. llama2기반의 baseline model인 openbuddy모델 기준으로 65422 token입니다. 그렇다면 이런 보고서가 1만 개 이상 있어야겠네요.
사실 이런 보고서 만 개는 모을 수 있을지도 모릅니다. 하지만 웬만한 회사에서는 내용이 겹치지 않는 양질의 보고서를 만 개 이상 분류해둔다는게 쉬운 일은 아니겠죠.
그래서 저희는 얼마만큼 적은 데이터로 학습을 시킬수 있을지 조사와 실험을 하였습니다. 다행히도 llama2의 부족한 한국어 능력을 미리 pretrain시켜둔 한국어 모델이 속속 등장하고 있어서 굳이 한국어를 익히게 하기위해 많은 데이터를 쏟아부어야할 필요는 없었습니다.
Textbooks Are All You Need 논문을 보면 1.3B짜리 모델에 7B데이터를 학습시켜서 더 크고 많이 학습시킨 다른 모델을 훨씬 뛰어넘는 결과를 얻었습니다. 이 논문에서 주장하는 바는 교과서의 연습문제 스타일의 데이터로 학습을 시켰더니 성능이 엄청나게 올랐다는 내용입니다. 물론 Stackoverflow와 선별된 교과서스타일의 내용자체로 pretrain도 시켰지만 말이죠.
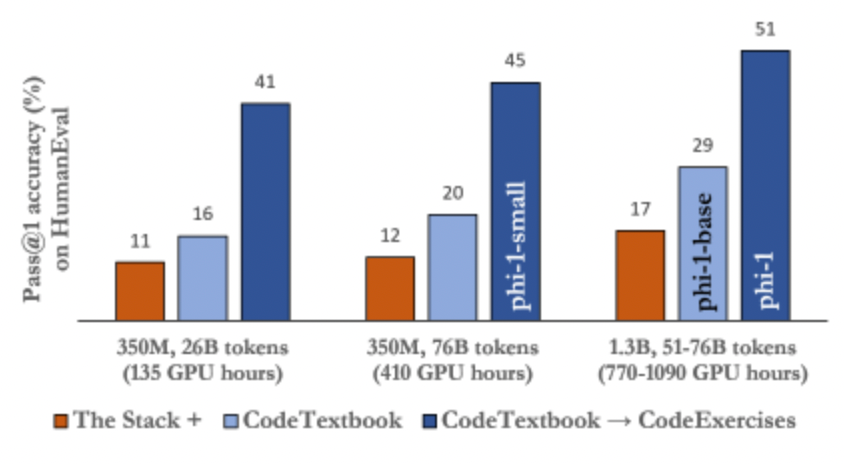
우리는 실험을 통해서 pretrain하는 과정을 제거해도 성능 저하가 크지 않음을 확인하였고 비용이 큰 pretrain단계를 생략하기로 했습니다.
그리고 BloombergGPT도 학습데이터의 절반은 금융이 아닌 일반 domain의 내용으로 학습하였습니다. 우리도 학습데이터의 절반은 일반데이터로 마련하였습니다. (사실 이 모든 내용을 미리 계획한 것이 아니라 이런저런 실험을 통해 최적화된 데이터 크기와 방법을 찾았다는게 맞습니다.)
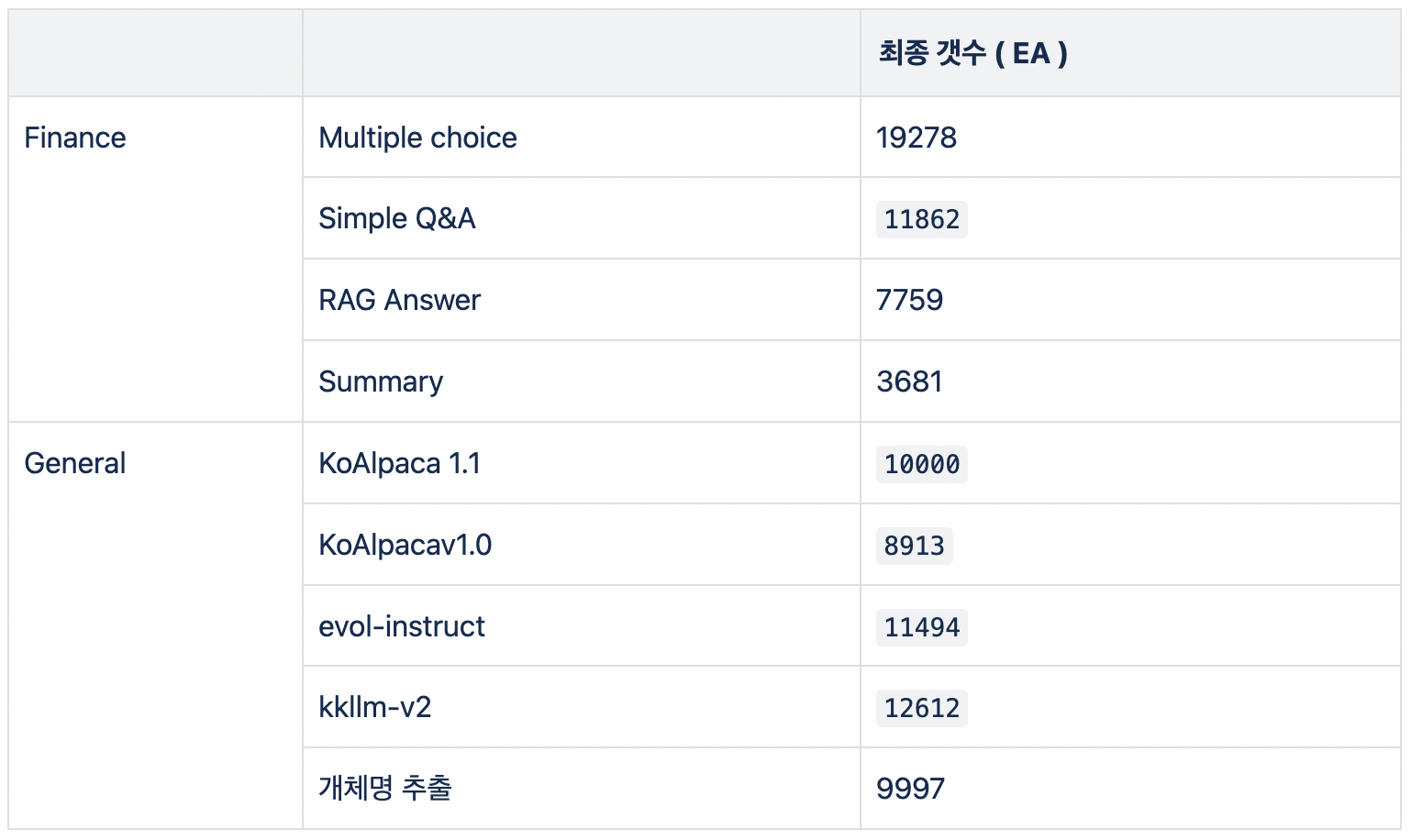
그래서 적용된 데이터 크기는 다음과 같습니다. 1개는 하나의 instruction과 기대하는 답변으로 이루어진 set입니다.
학습 데이터 모으기
올거나이즈는 LLM 이전에도 추출형 인지검색 모델을 서비스하고 있었기때문에 보고서나 용어집 등은 이미 보유하고 있었습니다. 양질의 보고서 데이터를 미리 확보한 셈이죠.
하지만 우리는 이를 교과서의 연습문제 스타일로 만들어야 했습니다. 이때 연습문제 스타일이란 결국엔 instruction set이 될 것입니다.
용어집을 통해서 만들수 있는 연습문제로 쉬운 것은 정의를 묻고 정의에 대해 답을 하는 것일 겁니다.(Simple Q&A)
이 데이터는 단순한 질문, 응답 패턴으로 생성할 수 있었습니다.
그리고 문서를 요약하는 작업도 있을 수 있습니다.(Summary)
이 데이터는 사람 손으로 대량의 데이터를 만들기는 어렵습니다. GPT-3.5에게 요약해달라고 시켜서 사용했습니다. GPT-3.5의 요약성능은 매우 뛰어나서 따로 검수할 필요성은 느끼지 못했습니다.
그리고 4지선다 문제를 생성하였습니다.(Multiple choice)
적절한 context를 제공하고 거기에 맞는 적절한 질문과 4지선다 답변을 생성하도록 했습니다. 이 문제를 바탕으로 문제를 푸는 instruction을 작성하였습니다.(Multiple choice) 단 이 경우에 너무 뻔하거나 쉬운 질문이 있을 수 있으므로 적어도 test data로 사용할 데이터는 사람이 검수해야했습니다. 일단 여러 개 생성한 후에 일부 좋은 질문들은 따로 test dataset으로 빼두었습니다.
그리고 이 과정에서 문제를 푸는 instruction뿐 아니라 문제를 생성하는 instruction역시 학습데이터로 사용할 수 있습니다.
마지막으로 RAG dataset을 만들었습니다. 적절한 context를 제공하고 거기에 맞는 질문을 생성합니다. 그리고 그 답변도 생성하였습니다. 이렇게 생성된 context, 질문, 답변 쌍을 사람이 전수 검사하여 올바른 질문과 답변인지 검수하였습니다.
그리고 추가로 관련이 있지만 질문에 직접적인 답이 존재하지 않는 hard negative clue을 2개를 선택하였습니다. 이렇게 생성된 3개의 clue를 Allganize summarize모델을 통해서 최대 token길이에 적당하도록 요약해서 RAG prompt와 답변 쌍을 만들 수 있었습니다.
일반적인 데이터는 이미 공개된 여러 데이터셋에서 너무 길거나 너무 짧거나 아니면 instruction이 없는 데이터를 제외하고 선택하여 만들었습니다.
성능 평가
LLM의 성능을 평가하기는 매우 어렵습니다. 생성모델이므로 답이 딱딱 떨어지는게 아니기 때문이지요. 조그만 차이때문에 내용이 완전히 달라지기도 하고 내용이 같다고해도 얼마나 매끄럽게 생성되는지도 판별해야합니다. 그리고 매번 사람이 평가할 수도 없습니다. 한두번 평가하고 말 것은 아니므로 기준이 있어야했습니다.
그래서 4지선다 문제를 웹에서 수집하였습니다. 하지만 양질의 4지선다 문제를 충분히 수집할 수 없었기때문에 GPT로 생성한 4지선다 문제중에서 괜찮은 문제를 사람이 선별하여 학습데이터에서 제외하고 평가데이터로 사용했습니다.
그래서 약 500여개의 평가셋을 만들수 있었고 그 데이터로 평가한 결과입니다.
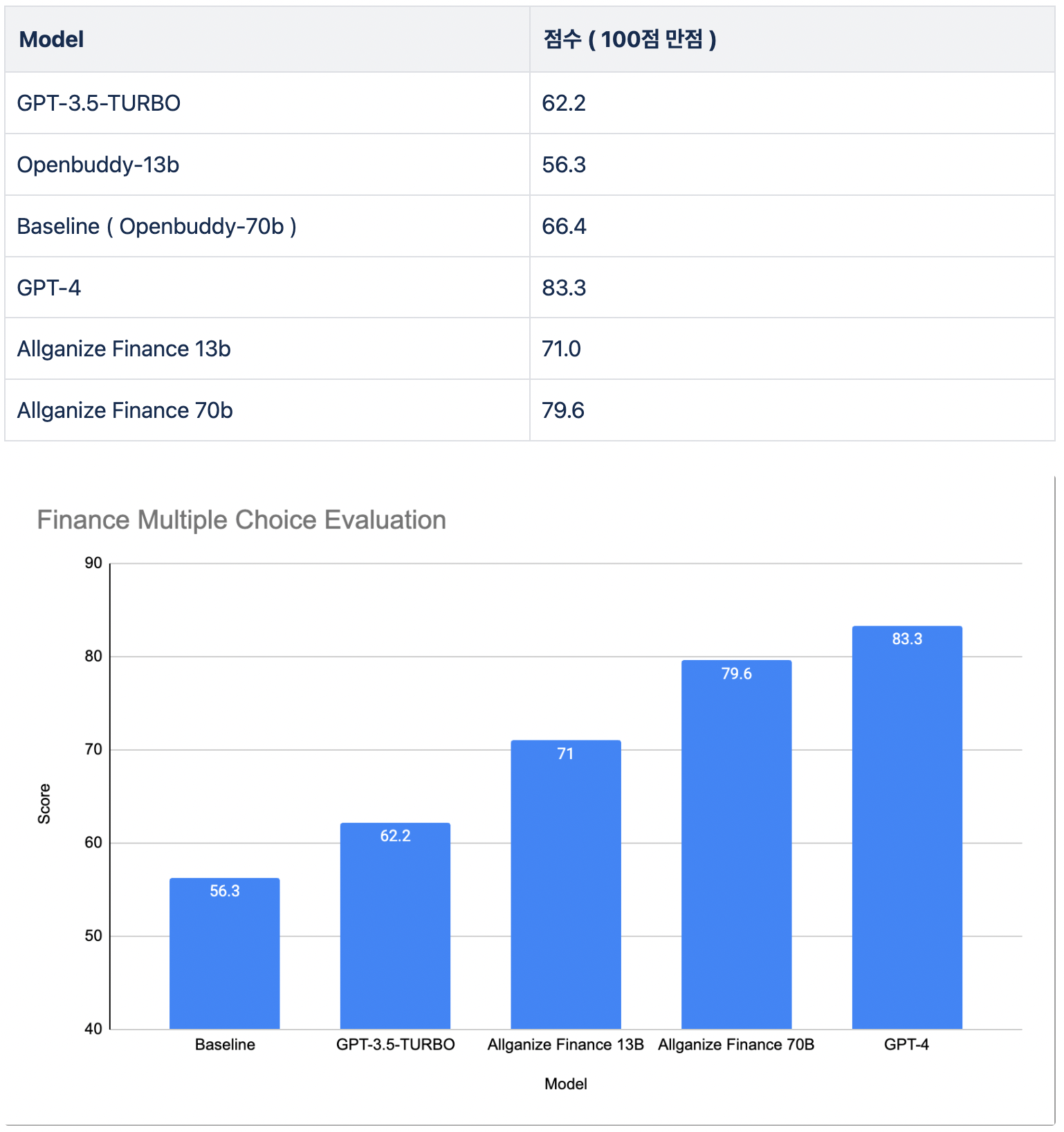
물론 이러한 4지선다 점수로 모든것을 평가할 수 없으므로 정성평가도 진행했습니다. 다만 특성상 많은 질문에 대해서 평가하지는 못하였고 그중 두 가지만 예로 들어보겠습니다. 아래는 RAG가 아니라 Zeroshot으로 질문을 한 결과입니다.

비용
데이터를 생성하는데는 GPT-4와 GPT-3.5(DAVINCI)를 이용하여 생성하였습니다. 총 800$정도의 OpenAI 비용과 검수 목적으로 8MD의 인력이 소요되었습니다.
학습비용은 13B의 경우는 160$정도의 GPU비용(AWS p4d.24xlarge 기준), 70B는 1000$정도의 GPU비용(AWS p4d.24xlarge 기준)이 들었습니다. 하지만 요즘은 p4d.24xlarge를 빌리기 너무 힘들어서 다른 GPU 제공회사의 장비를 빌려서 학습시켰습니다. 위 비용은 GPU Hour를 AWS 비용으로 환산한 결과입니다.
결론
OpenAI뿐 아니라 많은 회사들이 LLM들을 내놓고 있습니다. 오픈 소스 진영의 LLM의 성능 개선 역시 눈부실 정도입니다. 오픈 소스 진영은 chatgpt만큼 성능이 나와주지는 못해도 외부로 데이터가 흘러가지 않게 할 수 있는 큰 장점이 있습니다. 그리고 성능도 (학습만 시킨다면) 우리회사에 맞는 LLM을 확보할 수 있습니다. 물론 데이터를 손으로 만드는 것은 어렵지만 GPT를 이용해 학습 데이터를 만든다면 이 역시 손쉽게 해결 할 수 있습니다.
회사 내부에서 쓰이는 약어, 전문 용어를 이해하는 AI를 도입하고 싶다면, 우리 회사만의 LLM을 만드는 것도 빠르게 가능해졌습니다.
이제 실제로 기업용 LLM을 만들고 기업과 AI 프로젝트를 진행해온 올거나이즈와 함께 진행해보시면 어떨까요? AI 인프라부터 바로 쓸 수 있는 앱 마켓까지 모두 지금 가능합니다.