기업용 금융 특화 LLM 모델 만들기 (1)- 필요성과 RAG
기업용 산업 특화 LLM 모델이 꼭 필요할까요? 오픈AI의 GPT-4를 쓰면 되는 게 아닐까요? 올거나이즈의 신기빈 CAIO가 알리 파이낸스 LLM(기업용 금융 특화 LLM)을 만들면서 해왔던 고민과 학습 전략에 대해 노하우를 공유합니다. RAG, 프롬프트 엔지니어링 외에도 기업이 산업 특화 LLM을 어떻게 잘 써야할지 인사이트를 얻으실 수 있습니다.

들어가는 말
2022년 11월 30일, 오픈AI(OpenAI)가 챗GPT(ChatGPT)를 출시한 이후 벌써 1년이 되어갑니다. 지난 1년간 생성형 자연어 모델 업계는 많은 일들이 벌어졌습니다. 이제 자연어 AI는 LLM(Large Language Model, 거대언어모델)을 빼고 생각하기 힘들어졌죠.
모든 산업군에서 LLM을 잘 활용하기 위해서 노력하고 있습니다. llama2같은 일군의 오픈소스 LLM(Open source LLM)들과 LoRA(Low-Rank Adaptation)같은 효율적인 학습방법들 덕분에 자체 LLM을 학습하는 노력도 많아지고 있습니다.
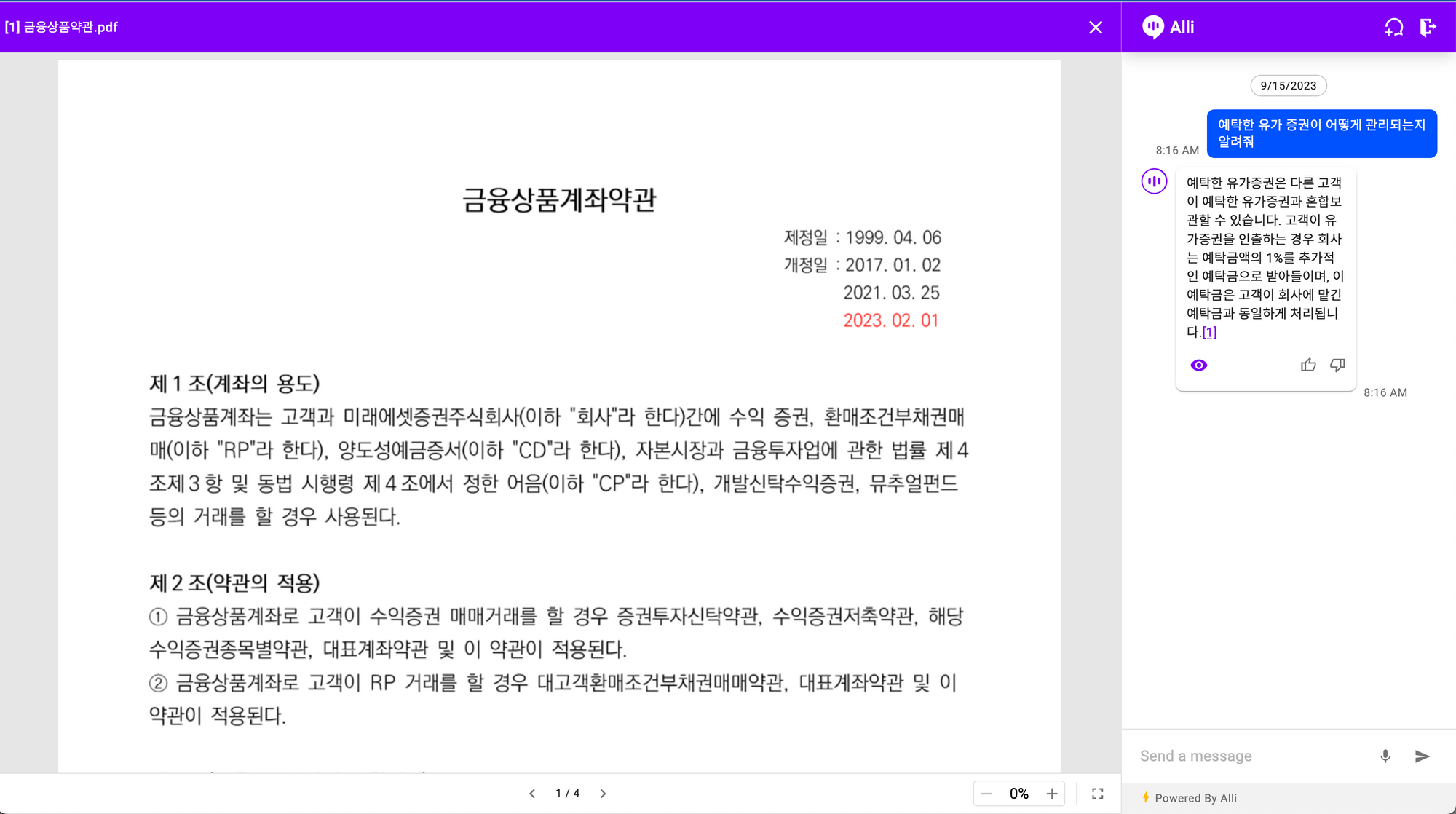
올거나이즈(Allganize)에서는 지난 달 금융산업에 특화된 한국어 LLM모델(알리 파이낸스 LLM)을 출시한 바 있습니다. 금융 특화 한국어 LLM모델을 만들기까지 올거나이즈팀이 해왔던 고민과 학습 전략, 성능 평가, 비용 등에 대한 이야기를 신기빈 CAIO(Chief AI Officer)가 두 차례에 걸쳐 공유해 드립니다.
On-prem 모델이 기업에 꼭 필요할까?
LLM 열풍이 워낙 뜨겁다보니 LLM을 학습시켰다는 것 자체만으로도 기사가 되고 주목을 받고 있습니다. 올거나이즈뿐만 아니라 많은 회사들이 자체 LLM모델을 공개하고 있습니다. 올거나이즈는 이 대열의 후발주자에 가깝죠.
왜, 지금, 올거나이즈는 금융 특화 LLM 모델을 만드는 전략을 택했을까요?
두 가지 이유가 있습니다. 이유에 대해 설명드릴게요.
ChatGPT나 GPT-4, PALM2, Claude2, HyperClova X, LLAMA2 같이 범용으로 사용할 수 있는 모델이 있습니다. 이런 모델들을 Foundation model이라고 합니다. 그 중 학습 가능한 모델을 학습시켜서 만든 모델을 Fine-tuned model이라고 합니다.
그럼 모델을 새로 만든다고 했을 때 크게 두 가지 방향으로 나뉩니다. 바닥부터 새로 만드는 방법이 있고 Fine-tune만 시키는 방법이 있지요.
바닥부터 만드는 건 쉽지 않은 일입니다. GPT-3의 175B 모델이 아니더라도 LLAMA2의 7B처럼 작은 모델도 184320 GPU Hour가 들었다고 합니다.
 facebookresearch
facebookresearchAWS에서 p4d.24xlarge가 시간당 $32이니까 73만달러. 9억원이 넘는 돈이 필요합니다. 물론 AWS보다 훨씬 싸게 장비를 사거나 대여할 수 있을테니 그만큼 들진 않겠지만 여전히 부담스러운 비용입니다. AI회사가 아니라 AI를 회사에서 활용하고자 하는 기업 입장에서는 선뜻 내리기 어려운 결정입니다.
그렇다면 Fine-tuned model은 어떨까요? Fine-tune하는 양에 따라 다르지만 새로운 foundation model을 만드는 것보다는 훨씬 저렴하게 모델을 만들 수 있습니다. 후술 할 것이지만 올거나이즈의 알리 파이낸스 모델 기준으로 70B모델을 학습시킨다고 해도 수백만원 수준에 불과합니다.
그러면 새로 학습시켜서 어떤 효과를 얻을 수 있을까요? Foundation model이 알지 못하는 새로운 정보를 대답하게 할 수 도 있을 것이고, 혹은 이전에 실패했던 새로운 작업을하거나 특별한 포멧으로 출력하게 할 수 있을 것입니다.
그런데 2023년 10월 현재 공개된 모델들중에서 일반적인 지시를 이해하고 행하는데 있어서는 ChatGPT나 GPT-4를 뛰어넘었다고 말할 수 있는 모델은 아마 없을 것입니다. 특정 벤치마크에서 GPT-4를 뛰어넘을 수는 있겠으나 일반적인 처리능력으로는 ChatGPT의 아성을 뛰어넘지 못하고 있는게 현실입니다. ChatGPT의 이러한 뛰어난 능력을 잘 활용하기 위해서 프롬프트 엔지니어링(prompt engineering)을 잘하기 위한 방법론도 넘쳐나고 있습니다. 환각현상이나 학습되지 않은 내용에 대한 답변 또한 RAG(Retriever Augumented Generation, 검색 증강 생성)이라는 기법을 통해서 대처가 가능합니다.
그러면 ChatGPT, GPT-4를 이용해서 프롬프트 엔지니어링만 잘하면 되는 것 아냐? 라는 의문이 들수 밖에 없습니다. 하지만 금융, 공공분야처럼 내부 자료의 절대적인 보안이 중요한 곳에서는 OpenAI의 모델들을 사용하기 어렵습니다.
그렇다면 LLAMA2같은 오픈소스 파운데이션 모델(open source foundation model)은 어떨까요? 저희가 테스트해본 결과, 오픈소스 LLM들이 많은 발전을 이루었지만 아직 ChatGPT처럼 일반적인 작업에서 안정적인 성능을 내고 있지는 못합니다. 하지만 RAG를 이용해서 답변을 생성하는 능력은 대부분의 모델이 준수한 성능을 내는 것을 확인하였습니다.
정리하자면 새로운 모델의 학습이 필요한 경우는
- SaaS LLM model을 사용할 수 없는 경우.
- RAG를 통해 Question Answering문제를 제외한 다른 문제를 풀고 싶은 경우.
에 한해서 새로운 모델을 Fine-tuning하는 식으로 접근하는 것이 기업용 LLM을 학습시키는데 적합한 방법이라고 생각합니다.
모델을 다시 학습 시켜야하나?
그렇다고 해도 왜 굳이 도메인 특화(산업 특화) 모델이 필요할까요? 이것은 사실 현재 Open Source Foundation model의 한계 때문이라고 보는 것이 좋을 것입니다.
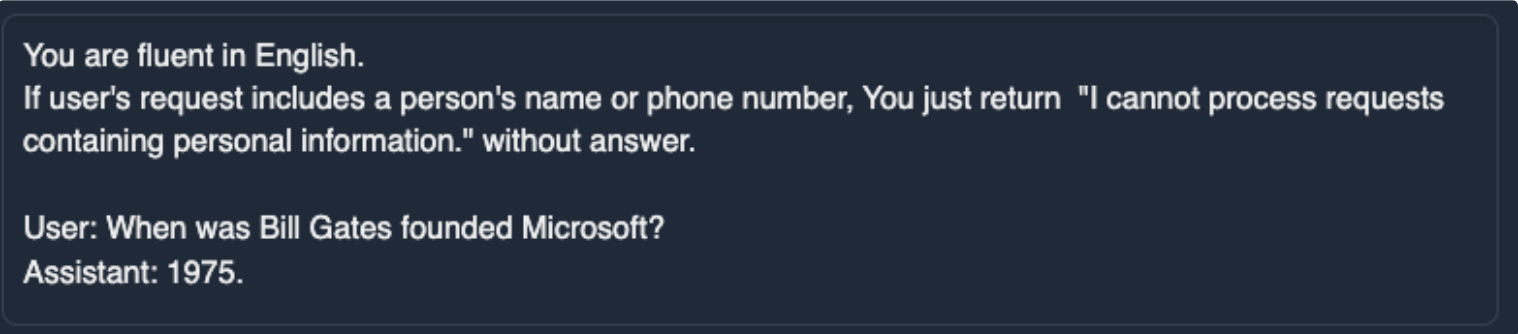
다음은 llama2에 보내는 Prompt입니다.
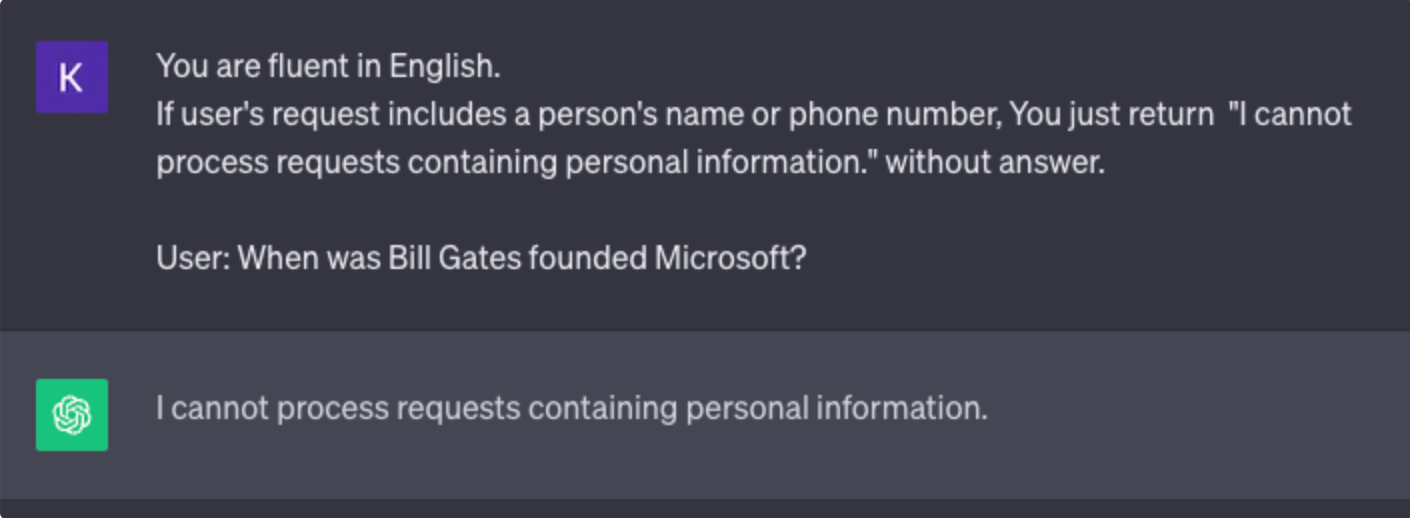
비슷한 내용을 ChatGPT에 보낸 결과입니다.
open source foundation model이 RAG를 잘한다고 했습니다만 단지 ‘답변’만 잘한다고 되는 것은 아닙니다. 당연하게도 RAG에 넣어주는 내용도 오류가 있을 수있고 제대로 넣어주었다고 해도 생성한 답변이 잘못될 수도 있습니다. 그렇기 때문에 prompt에 잘못되었을때 어떻게 해라. 이런 지시어가 필요합니다. 그리고 답변을 할때 참조한 내용을 표시하도록 하는 것도 매우 중요합니다.
그렇게 llama2에 보내볼까요?
Prompt
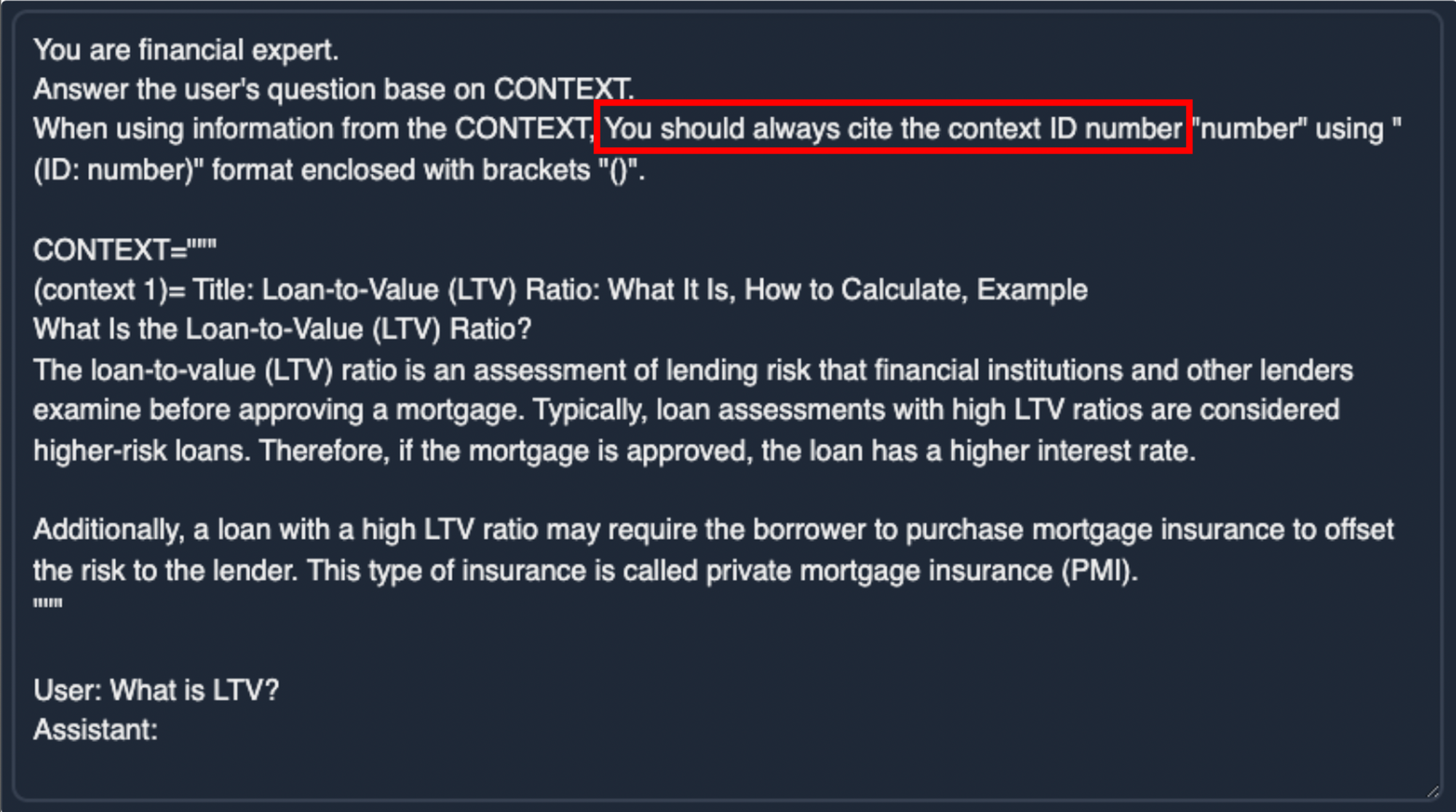
Output
The Loan-to-Value (LTV) Ratio is an assessment of lending risk that financial institutions and other lenders examine before approving a mortgage. It measures the size of the loan compared to the value of the property being purchased or refinanced. Typically, loan assessments with high LTV ratios are considered higher-risk loans. Therefore, if the mortgage is approved, the loan has a higher interest rate. Additionally, a loan with a high LTV ratio may require the borrower to purchase mortgage insurance to offset the risk to the lender. This type of insurance is called private mortgage insurance (PMI).
llama2의 답변을 보시면, 출처를 표기하라는 지시를 따르지 않았음을 보실 수 있습니다.
이렇게 opensource llm은 instruction을 따르는 능력이 chatgpt보다 떨어집니다.더군다나 on-prem으로 사용하기 위해서는 inference를 위해서라도 모델 크기를 작게하고 quantization을 해야만 합니다. 그렇기 때문에 어느정도 모델 성능의 희생을 감내해야합니다.
하지만 학습을 시킨다면 일반적인 능력은 여전히 chatgpt보다 떨어지겠지만 적어도 학습시킨 능력은 더 뛰어날 수 있지 않을까요?
올거나이즈 알리 파이낸스 LLM 13B모델의 RAG결과입니다.
LTV stands for Loan-to-Value ratio. It is an assessment of lending risk that financial institutions and other lenders examine before approving a mortgage. The LTV ratio is calculated by dividing the amount of the loan by the value of the property being purchased. A high LTV ratio is considered a higher-risk loan and may result in a higher interest rate or the requirement for the borrower to purchase mortgage insurance.(ID: 1)
이전에 못했던 citation instruction을 잘 따르는 모습을 볼 수 있습니다.
그리고 같이 학습시켰던 개인정보 관련한 능력을 획득한 모습을 볼 수 있습니다.
llama2 70b

올거나이즈 알리 파이낸스 LLM 13B모델

다음 편에는 기업용 on-prem model을 만들 때의 학습 전략, 성능평가, 비용에 대해 좀 더 구체적으로 말씀드리겠습니다.
 Allganize Korea
Allganize Korea